0 Postgresql存储、索引及系统优化、主备切换
1 Postgresql存储
1.1 数据(表)逻辑结构
1.1.1 数据库逻辑结构介绍
在一个PostgreSQL数据库系统中,数据的组织结构可以分为以下3层。
- 数据库:一个PostgreSQL数据库服务可以管理多个数据库,当应用连接到一个数据库时,一般只能访问这个数据库中的数据,而不能访问其他数据库中的内容(除非使用DBLink等其他手段)。
- 表、索引:一个数据库中有很多表、索引。一般来说,在PostgreSQL中表的术语为“Relation”,而在其他数据库中则叫“Table”。
- 数据行:每张表中都有很多行数据。在PostgreSQL中行的术语一般为“Tuple”,而在其他数据库中则叫“Row”。
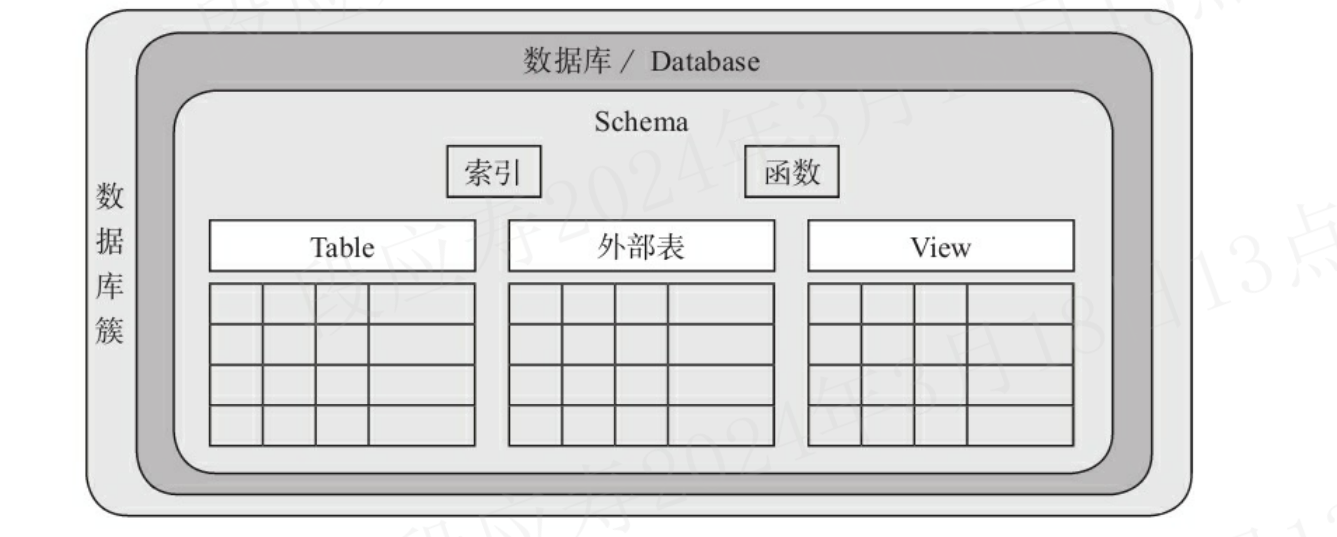
在PostgreSQL中,逻辑对象是有层次关系的,数据库创建后,有一个叫数据库簇的概念,虽然数据库簇的英文为database cluster,但它并不是数据库集群的意思,故而翻译为数据库簇。在数据库簇中可以创建很多数据库(使用create database创建),也就是说,数据库簇相当于是一个数据库的容器。而PostgreSQL中的database与MySQL中的Database完全不是一个概念,PostgreSQL的Database是一个多租户的概念,与Oracle 12C的Pluggable Database类似,主要实现租户隔离。在Database下,可以有多个模式(Schema),数据库逻辑存储结构的层次关系下图所示。
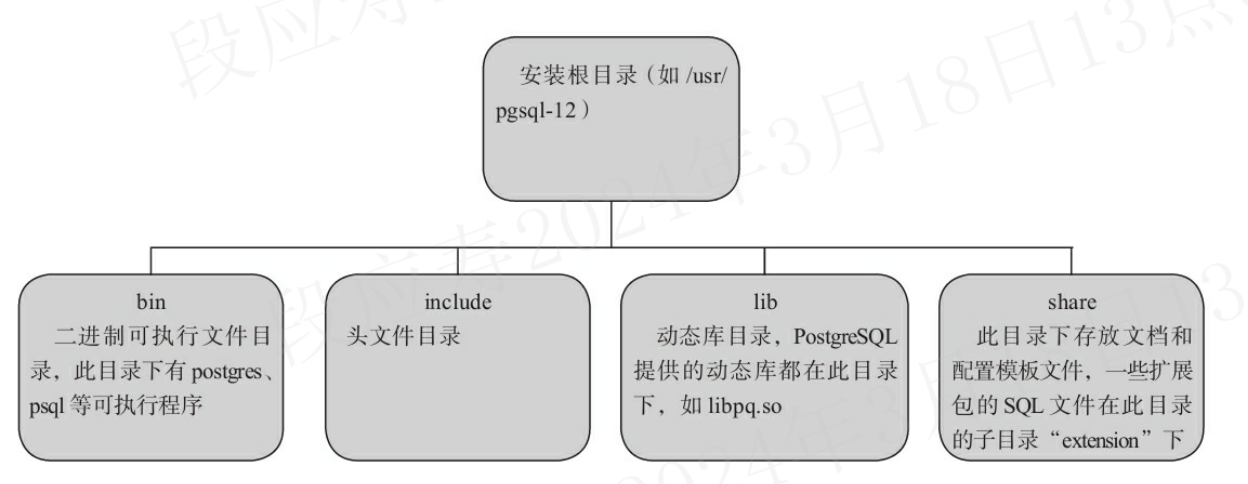
pg安装后,其安装目录如下:
1.1.2 磁盘文件
一般使用环境变量PGDATA指向数据目录的根目录。该目录是在安装时指定的,所以在安装时需要指定一个合适的目录作为数据目录的根目录,而且每一个数据库实例都需要一个根目录。目录的初使化是使用initdb来完成的,初始化完成后,数据根目录下就会生成以下6个配置文件。
- postgresql.conf:此数据库实例的主配置文件,基本上所有的配置参数都在此文件中。
- postgresql.auto.conf:使用ALTER SYSTEM修改的配置参数存储在该文件中(PostgreSQL 9.4及更高版本)。
- pg_hba.conf:认证配置文件,用于配置允许哪些IP的主机访问数据库、认证的方法是什么等信息。
- pg_ident.conf:ident认证方式的用户映射文件。
- PG_VERSION:存储PostgreSQL主版本号。
- postmaster.opts:记录服务器上次启动的命令行参数。
root@eb2e0ae36696:/var/lib/postgresql/data# echo $PGDATA
/var/lib/postgresql/data
root@eb2e0ae36696:/var/lib/postgresql/data# ls -l /var/lib/postgresql/data | grep ^-
-rw------- 1 postgres postgres 4924 Feb 21 08:01 pg_hba.conf
-rw------- 1 postgres postgres 1636 Feb 20 08:16 pg_ident.conf
-rw------- 1 postgres postgres 3 Feb 20 08:16 PG_VERSION
-rw------- 1 postgres postgres 88 Feb 20 08:16 postgresql.auto.conf
-rw------- 1 postgres postgres 26818 Feb 21 08:06 postgresql.conf
-rw------- 1 postgres postgres 36 Mar 14 06:39 postmaster.opts
-rw------- 1 postgres postgres 94 Mar 14 06:39 postmaster.pid
root@eb2e0ae36696:/var/lib/postgresql/data# cat postmaster.opts
/usr/lib/postgresql/12/bin/postgres
root@eb2e0ae36696:/var/lib/postgresql/data# cat postmaster.pid
1
/var/lib/postgresql/data
1710398366
5432
/var/run/postgresql
*
5432001 0
ready
数据目录的根目录下还会生成如下子目录。
- base:默认表空间的目录。
- global:一些共享系统表的目录。
- log:程序日志目录,在查询一些系统错误时可查看此目录下的日志文件。在10版本之前此目录是“pg_log”。
- pg_commit_ts:视图提交的时间戳数据(PostgreSQL 9.5及更高版本)。
- pg_dynshmem:动态共享内存子系统使用的文件(PostgreSQL 9.4及更高版本)。
- pg_logical:逻辑复制的状态数据(PostgreSQL 9.4及更高版本)。
- pg_multixact:多事务状态数据。
- pg_notify:LISTEN/NOTIFY状态数据。
- pg_repslot:复制槽数据(PostgreSQL 9.4及更高版本)。
- pg_serial:已提交的可串行化事务相关信息(PostgreSQL 9.1及更高版本)。
- pg_snapshots:PostgreSQL函数“pg_export_snapshot”导出的快照信息文件(PostgreSQL 9.2及更高版本)。
- pg_stat:统计子系统的永久文件。
- pg_stat_tmp:统计子系统的永久文件。
- pg_subtrans:子事务状态数据。
- pg_tblsp:存储了指向各个用户自建表空间实际目录的链接文件。
- pg_twophase:使用两阶段提交功能时分布式事务的存储目录。
- pg_wal:WAL日志的目录,在PostgreSQL 10版本之前此目录是“pg_xlog”。
- pg_xact:Commit Log的目录,在PostgreSQL 10版本之前此目录是“pg_clog”。
root@eb2e0ae36696:/var/lib/postgresql/data# ls -l /var/lib/postgresql/data | grep ^d
drwx------ 5 postgres postgres 41 Feb 20 08:16 base
drwx------ 2 postgres postgres 4096 Mar 14 06:40 global
drwx------ 2 postgres postgres 6 Feb 20 08:16 pg_commit_ts
drwx------ 2 postgres postgres 6 Feb 20 08:16 pg_dynshmem
drwx------ 4 postgres postgres 68 Mar 14 06:44 pg_logical
drwx------ 4 postgres postgres 36 Feb 20 08:16 pg_multixact
drwx------ 2 postgres postgres 18 Mar 14 06:39 pg_notify
drwx------ 2 postgres postgres 6 Mar 7 12:05 pg_replslot
drwx------ 2 postgres postgres 6 Feb 20 08:16 pg_serial
drwx------ 2 postgres postgres 6 Feb 20 08:16 pg_snapshots
drwx------ 2 postgres postgres 6 Mar 14 06:39 pg_stat
drwx------ 2 postgres postgres 63 Mar 18 06:18 pg_stat_tmp
drwx------ 2 postgres postgres 18 Feb 20 08:16 pg_subtrans
drwx------ 2 postgres postgres 6 Feb 20 08:16 pg_tblspc
drwx------ 2 postgres postgres 6 Feb 20 08:16 pg_twophase
drwx------ 3 postgres postgres 124 Mar 7 12:10 pg_wal
drwx------ 2 postgres postgres 18 Feb 20 08:16 pg_xact
在默认表空间的base目录下有很多子目录,这些子目录的名称与相应数据库的OID相同。
root@eb2e0ae36696:/var/lib/postgresql/data# psql -U postgres
psql (12.8 (Debian 12.8-1.pgdg110+1))
Type "help" for help.
postgres=# select oid, datname from pg_database;
oid | datname
-------+-----------
13458 | postgres
1 | template1
13457 | template0
(3 rows)
比如我们新创建一个test数据库,它的oid为16405,此时在base目录下就会生成一个16405的目录。
postgres=# create database test;
CREATE DATABASE
postgres=# select oid, datname from pg_database;
oid | datname
-------+-----------
13458 | postgres
16405 | test
1 | template1
13457 | template0
(4 rows)
postgres=# \c test;
You are now connected to database "test" as user "postgres".
root@eb2e0ae36696:/var/lib/postgresql/data# ls base -al
total 52
drwx------ 6 postgres postgres 54 Mar 18 06:27 .
drwx------ 19 postgres root 4096 Mar 14 06:39 ..
drwx------ 2 postgres postgres 8192 Feb 20 08:16 1
drwx------ 2 postgres postgres 8192 Feb 20 08:16 13457
drwx------ 2 postgres postgres 8192 Mar 14 06:40 13458
drwx------ 2 postgres postgres 8192 Mar 18 06:29 16405
在16405目录下,存放着“test”这个数据库的表、索引等数据文件。每个表或索引都会分配一个文件号relfilenode,数据文件格式则以“<relfilenode>[.顺序号]”命名,每个文件最大为1GB,当表或索引的内容大于1GB时,就会从1开始生成顺序号。所以一张表的数据文件的路径为:
<默认表空间的目录>/<database oid> /<relfilenode>[.顺序号]
我们在test数据库下面创建一张test表,同时创建一个索引。
test=# \d
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | test | table | postgres
(1 row)
test=# select * from test;
id | name
----+------
(0 rows)
test=# create index test_index on test(id);
CREATE INDEX
test=# \d
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | test | table | postgres
(1 row)
test=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
Indexes:
"test_index" btree (id)
test=#
而一张表或索引的“relfilenode”是记录在系统表pg_class的relfilenode字段中的。如果要查询数据库“tes”中表“test”的数据文件,根据前面已经查出的数据库“test”的oid(为16405)来查,假设表“test01”是在默认表空间下的,那么查询这张表的relfilenode的命令如下:
test=# select relnamespace, relname, relfilenode from pg_class where relname='test';
relnamespace | relname | relfilenode
--------------+---------+-------------
2200 | test | 16406
(1 row)
可以看出这个表的relfilenode为“33103”,则这张表的数据文件为“$PGDATA/base/16405/16406”:
root@eb2e0ae36696:/# ls $PGDATA/base/16405/16406 -al
-rw------- 1 postgres postgres 0 Mar 18 06:35 /var/lib/postgresql/data/base/16405/16406
同样的查看索引文件test_index,
est=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
Indexes:
"test_index" btree (id)
test=# select relnamespace, relname, relfilenode from pg_class where relname='test_index';
relnamespace | relname | relfilenode
--------------+------------+-------------
2200 | test_index | 16412
(1 row)
可以看出这个索引的relfilenode为“16412”,则这张表的数据文件为“$PGDATA/base/16405/16412”:
root@eb2e0ae36696:/# ls $PGDATA/base/16405/16412 -al
-rw------- 1 postgres postgres 8192 Mar 18 06:53 /var/lib/postgresql/data/base/16405/16412
1.2 数据(表)物理存储结构
Postgresql当前不支持使用裸设备或者块设备,必须基于文件系统来存储。
1.2.1 关键概念
- Realation:表示表或索引。
- Tuple:表示表中的行。
- Page:表示在磁盘中的数据块。
- Buffer:表示在内存中的数据块
1.2.2 数据块结构
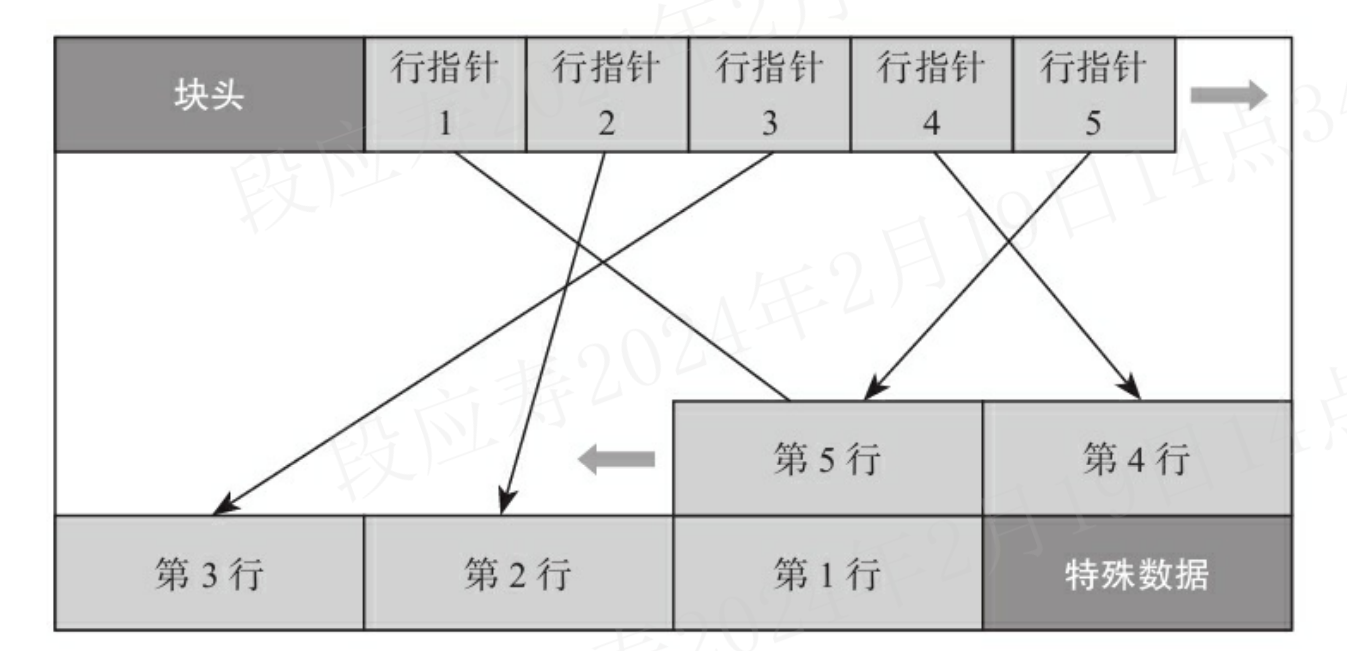
数据块是多行数据的存储结构。
数据块的大小默认是8KB,最大是32KB,一个数据块里存储了多行数据,其数据存储方式采用两头向中间靠拢的方式。 最前面是块头,块头后面记录了各个数据行的指针,数据行从块尾向中间排列,直到和行指针相遇(即没有空间存放新的行数据)。 行数据指针与行数据之间的部分就是空闲空间。数据块存储结构如下图所示:
1.2.2.1 块头
块头主要记录了如下信息:
- 块的checksum
- 空闲空间的起始位置和结束位置
- 特殊数据的起始位置 块头的代码结构如下所示:
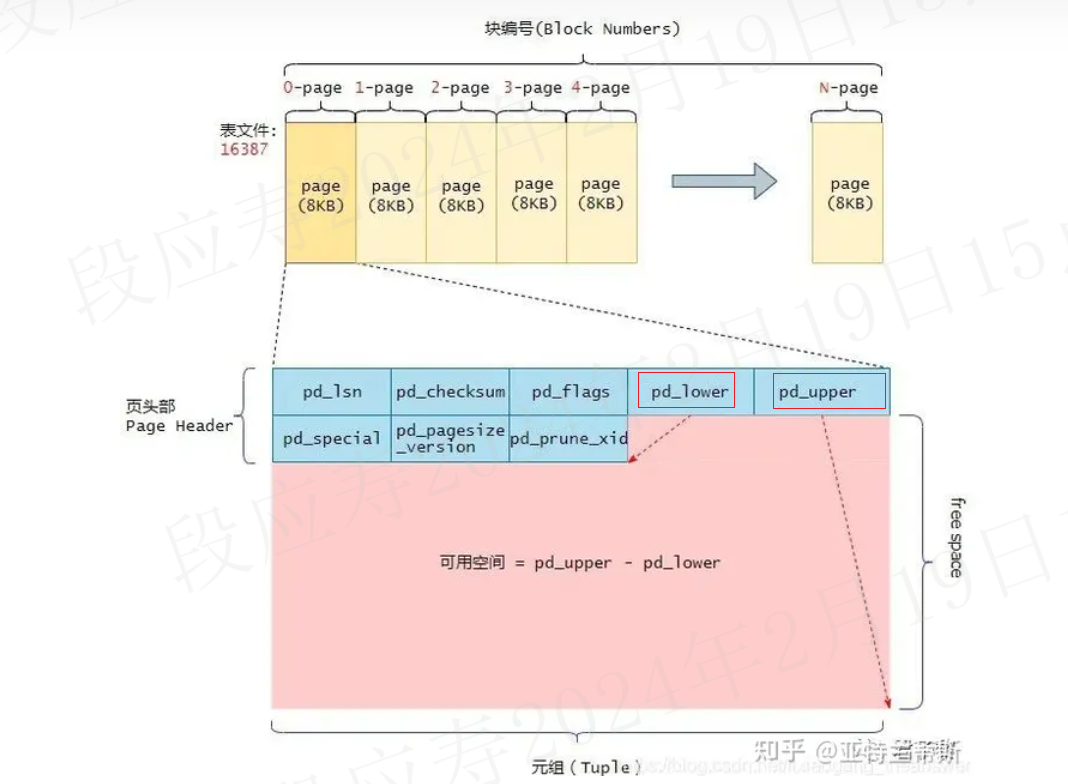
typedef struct PageHeaderData
{
PageXLogRecPtr pd_lsn; /*本页最后一次更改所写入的XLOG记录的LSN(即当前WAL位置)*/
uint16 pd_checksum; /* 本页数据的checksum */
uint16 pd_flags; /*标志位*/
LocationIndex pd_lower; /* 空闲空间的起始偏移位置 */
LocationIndex pd_upper; /* 空闲空间的结束偏移位置 */
LocationIndex pd_special; /* 指向特殊空间的起始偏移量 */
uint16 pd_pagesize_version; /* 页面大小及页面版本号 */
TransactionId pd_prune_xid; /* 可删除的旧XID,如果没有则为零 */
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* 行指针数组(变长数组),它指向该页中的元组(也就是表记录) */
} PageHeaderData;
pd_flags可取值如下:
//是否有未使用的行指针?
#define PD_HAS_FREE_LINES 0x0001
//没有足够的空间容纳新元组?
#define PD_PAGE_FULL 0x0002
//页面上的所有元组对每个人都可见?
#define PD_ALL_VISIBLE 0x0004
//所有有效pd_flags位的OR操作
#define PD_VALID_FLAG_BITS 0x0007
当向表中插入数据时,postgres会分配8KB(BLCKSZ)的内存空间。 除了页的头部数据占用的空间外,其余的空间都是可用于存储元组的(当然行指针也有占用空间)。 当没有行数据时,pd_upper指向可用空间(空闲空间)的末尾,而pd_lower指向页头(PageHeaderData)之后的第一个空闲空间的起始位置。 pd_upper - pd_lower是该页中剩余可用的空闲空间,随着元素的不断插入,pd_upper和pd_lower变量会不断地随着更新。
1.2.2.2 行指针
行指针是一个32bit的数字,具体结构如下:
typedef struct ItemIdData
{
unsigned lp_off:15, /* 行内容的偏移量 */
lp_flags:2, /* 指针的标记位 */
lp_len:15; /* 行内容的长度 */
} ItemIdData;
行指针中表示行内容在业内(块中)的偏移量是15bit,能表示的最大偏移量是2^15=32768,因此在Postgresql中的最大大小是32KB。
行指针的长度为4个字节,它形成一个简单的(ItemId,行指针)数组,该数组起着元组索引的作用。每个索引编号从1开始,称为“偏移数”。
当将一个新的元组添加到页的时候,新的行指针也被添加到pd_linp数组中,以指向其对应的元组。
当不断向页中插入数据时候,其元组、行指针以及可用空间的变化如下图所示:
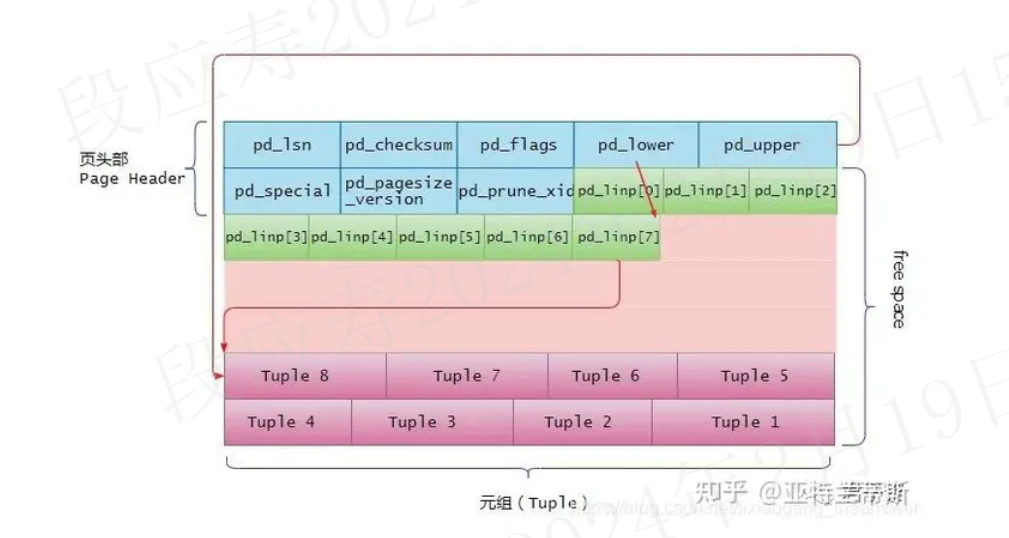
当向页中插入一行数据时,需要做如下几件事情:
- 更新行指针的页偏移位置和行长度;
- 将行数据插入到指定位置;
- 更新页空闲空间的起始位置和结束位置;
- 重新计算checksum;
如何读取存储的行数据呢?
页头大小是固定的,同时pd_lower记录了空闲空间的起始位置,且行指针的长度是固定的32bit(4字节),根据这三个数据就可以计算有多少行数据。
n = (pd_lower - sizeof(PageHeaderData))/4
访问的时候先从页头的尾部开始依次访问行指针,根据lp_off确定行的起始位置,根据lp_off+lp_len确定行的结束位置。
1.2.3 tuple结构
这里的tuple指的是数据行,就是前面提到的块(页)结构中行指针所指向的数据。
tuple的物理结构同样是先有一个行头,后面跟了各项数据。
tuple的结构如下图:
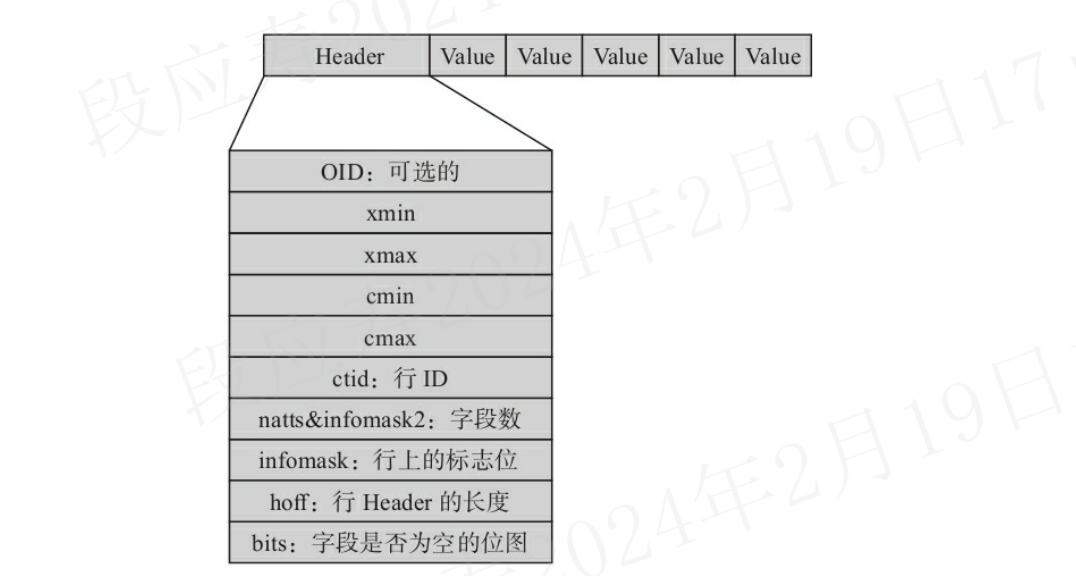
1.2.3.1 行头
行头的结构体定义如下:
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* 一个行版本在它所处的表内的物理位置 */
/* Fields below here must match MinimalTupleData! */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
uint16 t_infomask2; /* 字段数,其中低11位表示这行有多少个列。其他的位则是HOT(Heap Only Touples)技术及行可见性的标志位。 */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* 用于标识行当前的状态,比如行是否具有OID,是否有空属性,共有16位
,每位都代表不同的含义 */
#define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4
uint8 t_hoff; /* 表示行头的长度 */
/* ^ - 23 bytes - ^ */
#define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* 是一个数组,用于标识该行上哪些字段(列)为空 */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
其中t_choice成员变量是一个共用体数据类型。对于t_choice中的t_heap成员,它描述了当前元组的事务id、事务id等信息,如下:
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* 插入该行版本的事务ID,对应用户看到的xmin */
TransactionId t_xmax; /* 删除此行时的事务ID,第一次插入时,此字段为0。如果查询出来此字段不为0,则可能是删除这行的事务还未提交,或者是删除此行的事务回滚了,对应用户看到的xmax */
union
{
CommandId t_cid; /* 插入或者删除id,或者同时是插入和删除id,其实就是cmin和cmax */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
1.2.3.2 行头关键字段
- xmin 插入数据行的事务ID。
- xmax 删除数据行的事务ID。
xmin和xmax是如何更新的?
- 新插入一行时,将新插入行的xmin设置为当前的事务ID,xmax为0,因为没有删除;
- 修改一行时,因为MVCC机制,实际上是新插入一行。原数据行上的xmin不变,xmax更新为当前的事务ID(因为修改时,原数据行相当于删除了,即标记删除)。而新插入的数据行的xmin设置为当前的事务ID,xmax设置为0,因为没有删除;
- 删除一行时,把被删除行上的xmax填写为当前的事务ID。
如何根据xmin和xmax确定访问哪个tuple?
PG中每个表都包含了一些系统字段,其中包括cmin和cmax
- cmin 插入该元组的命令在插入事务中的命令标识(从0开始累加)
- cmax 删除该元组的命令在插入事务中的命令标识(从0开始累加)
简单来说,cmin和cmax都是表示tuple的command id,即cmin是产生该条tuple的command id,cmax是删除该tuple的command id。 cmin和cmax用于判断同一个事务内的其他命令导致的行版本变更是否可见。如果一个事务内的所有命令严格顺序执行,那么每个命令总能看到之前该事务内的所有变更,不需要使用命令标识。
行上记录了操作这行的命令ID,当其他命令读取这行数据时:
- 如果当前的命令ID大于等于数据行上的命令ID,说明这行数据是 可见的;
- 如果当前的命令ID小于数据行上的命令ID,则这条数据不可见
为什么这里有cmin和cmax两个字段,但在实际的结构体里却没有对应的字段?
在每个tuple的头部,这两个字段都是存放在t_cid中,其长度为4bytes。 在PG8.3版本前,cmin和cmax确实是分别存放在不同字段中的,但是从8.3版本开始,为了减少cmin和cmax对heap page空间的占用,将这两个字段都存放在t_cid中了,即combo cid。 一般来说,当我们的事务中只是插入数据时,t_cid存储的就是cmin,因为此时也只有cmin是有效的。而当进行了update或者delete操作时,才会产生cmax。当这种既有cmin又有 cmax的情况,即在同一个事务中既有插入又有更新的时候,t_cid存储的就是combo cid(组合cid)。
如何判断是combo cid?
使用到tuple中的标志位infomask,combo cid的标志位是HEAP_COMBOCID,其值是0x0020。定义如下:
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo CID */
在通过HeapTupleHeaderGetCmin/HeapTupleHeaderGetCmax获取cmin或者cmax的时候,首先会通过头部的控制字段判断tuple->t_infomask & HEAP_COMBOCID,如果是combo cid,那么通过这个cmobo cid字段,获取真正的cmin或者cmax。
如何通过combo cid获取cmin和cmax?
cmin和cmax存储在ComboCidKeyData结构中。其定义如下:
/* Key and entry structures for the hash table */
typedef struct
{
CommandId cmin;
CommandId cmax;
} ComboCidKeyData;
typedef ComboCidKeyData *ComboCidKey;
typedef struct
{
ComboCidKeyData key;
CommandId combocid;
} ComboCidEntryData;
事务在第一次更新本事务插入的tuple时,会新开辟一个数组ComboCidKey comboCids; 其大小初始的时候为100(每次空间不够的时候,会将数组的大小的扩大2倍)。 同时还会使用一个hashmap,用来根据ComboCidKeyData查找combo cid。
comboHash = hash_create("Combo CIDs",
CCID_HASH_SIZE,
&hash_ctl,
HASH_ELEM | HASH_BLOBS | HASH_CONTEXT);
将combo cid存储映射cmin/cmax,在update/delete本事务中插入的tuple时,调用GetComboCommandId函数,生成一个combo cid存储在tuple头部原来的cmin/cmax域。大致流程如下:
- 首先根据(cmin, cmax)查找comboHash,如果找到返回ComboCidEntryData中的combo cid(reuse机制, 这个hashmap的作用);
- 如果没找到,往comboCids数组中添加一个ComboCidKeyData元组,同时往hashmap插入一个entry。返回的combo cid为usedComboCids(comboCids数组当前的大小),然后usedComboCids++。
获取真正的cmin和cmax,通过tuple header上的combo cid,直接作为下标到comboCids返回对应的元组。相当于使用combo cid作为key,(cmin,cmax)作为value保存在hash表中,当根据tuple的infomask确定为combo cid时,就使用t_cid进行查找,进而得出cmin,和cmax。
为什么有了xmin,xmax后,还需要有cmin和cmax?
xmin,xmax,cmin,cmax都是为了实现MVCC机制而引入的。其中xmin,xmax是在事务级别控制行的可见性,当一个事务存在多条命令时(插入、更新、删除),就需要使用cmin,cmax来控制事务内命令级别行的可见性。
- infomask 行上的xmin、xmax、cmin、cmax和CLOG日志一起用于控制行的可见性。 每个事务在CLOG中占用两个bit,数据库运行一段时间后,如几年,就可能产生上亿个事务,最多时甚至可能达到20亿个事务,它们使用的CLOG可能占用512MB的空间,在这么大的CLOG中查询事务的状态,效率可能不高,于是PostgreSQL对查询行的可见性做了优化,把一些可见性的信息记录在infomask字段上,该字段的t_infomask中有以下与可见性相关的标志位:
#define HEAP_HASNULL 0x0001 /* has null attribute(s) */
#define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) */
#define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */
#define HEAP_HASOID_OLD 0x0008 /* has an object-id field */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo CID */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
/* xmax is a shared locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */
#define HEAP_UPDATED 0x2000 /* this is UPDATEd version of row */
#define HEAP_MOVED_OFF 0x4000 /* moved to another place by pre-9.0
* VACUUM FULL; kept for binary
* upgrade support */
#define HEAP_MOVED_IN 0x8000 /* moved from another place by pre-9.0
* VACUUM FULL; kept for binary
* upgrade support */
#define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
#define HEAP_XACT_MASK 0xFFF0 /* visibility-related bits */
如果t_infomask中HEAP_XMIN_COMMITTED为真,而HEAP_XMAX_INVALID为假,则说明该行是新插入的行,是可见的,此时就不需要到CLOG中查询xmin和xmax的事务状态了。
而如果未设置HEAP_XMIN_COMMITTED,并不表示该行没有提交,而是说不知道xmin是否提交了,需要到CLOG中去判断xmin的状态。HEAP_XMAX_COMMITTED也是如此。
第一次插入数据时,t_infomask中的HEAP_XMIN_COMMITTED和HEAP_XMAX_INVALID并未设置,但当事务提交后,有用户再读取这个数据块时会通过CLOG判断出这些行的事务已提交,会设置t_infomask中的HEAP_XMIN_COMMITTED和HEAP_XMAX_INVALID标志位。
下次再查询该行时,直接使用t_infomask中的HEAP_XMIN_COMMITTED和HEAP_XMAX_INVALID标志位就可以判断出行的可见性了,不再需要到CLOG中查询 事务的状态。
1.2.3.3 MVCC实现原理
1.2.3.3.1 事务内部的多版本一致
xmin、xmax、cmin、cmax这四个字段在MVCC中用于控制数据行是否对用户可见。PG会将修改前后的数据都存储在相同的结构中
-
新插入一行时,将新插入行的xmin填写为当前事务ID,xmax填0
-
修改某一行时,实际上是新插入一行,旧行上的xmin不变,旧行上的xmax改为当前事务ID,新行上的xmin填为当前事务ID,新行上的xmax填为0
-
删除一行时,把被删除行上的xmax填为当前事务ID
-
cmin和cmax用于判断同一个事务内的不同命令导致的行版本变化是否可见,每个命令使用事务内一个命令标识计数器的值作为当前命令标识,事务开始时,命令标识计数器被置为0。执行一条DML后,命令标识计数器加1,当命令标识计数器不断累加又循环到0时,会报错,因为一个事务中命令的个数最多为2^32-1个,当某个事务内的命令读到某行数据时,会根据cmin和cmax做出判断:
- 若当前命令ID>=当前行的cmax且cmax不等于0,说明当前行对此命令不可见
- 若当前命令ID>=当前行的cmin,说明当前行对此命令可见
1.2.3.3.2 不同事务间的多版本一致
PG是通过数据行上的xmin和xmax来判断对某事务是否可见,那么只需要确认xmin和xmax对应的事务是提交了还是回滚了,就可以知道这些数据行是否可见。PG把事务状态记录在commit log中,简称clog,事物的状态有以下四种:
- TRANSACTION_STATUS_IN_PROGRESS =0X00:表示事务正在进行中
- TRANSACTION_STATUS_COMMITTED =0X01:表示事务已提交
- TRANSACTION_STATUS_ABORTED =0X02:表示事务已回滚
- TRANSACTION_STATUS_SUB_COMMITTED =0X03:表示子事务已提交
事务ID有时会缩写为XID,是一个32bit的数字。有三个特殊的事务ID是给系统内部使用的,如下:
- InvalidTransactionId=0:表示是无效的事务id
- BootstrapTransactionId=1:表示系统表初始化时的事务id
- FrozenTransactionId=2:冻结的事务id
由上可知,正常事务ID是从3开始的,然后不停递增,达到最大值后,再从3开始。事务ID 0、1、2的始终保留。
若事务ID一直递增,总会到达4字节整数的最大值,达到最大值后再从头开始时,就会出现之前事务ID比当前事务ID大,而在比较时,就会认为以前事务ID是将来的事务ID,这自然会导致严重的问题,即事务ID回卷的问题。
在事务ID没有回卷时,简单比较两个事务ID的大小就知道事务之间的先后关系,但当事务ID回卷后,简单的比较大小就不行了。
为了解决事务回卷和满足满足比较事务新旧的需求,在PG中规定,最旧和最新事务之间的年龄差最大为2^31,而不是无符号整数的最大范围2^32,当事务ID要超过2^31时,就把旧事务换成一个特殊的事务ID,也就是FrozenTransactionId的特殊事务。
当正常事务ID与冻结事务ID比较时,会认为正常事务ID比冻结事务ID新。然后对于普通的事务比较新旧时就可以套用如下公式了:
((int32) (id1 - id2)) < 0
从这个公式中可以看出 ,当事务ID没有回卷时,上面的公式相当于直接比较大小,在事务ID回卷后,如id1=4294967295,id2=5,id1-id2=4294967290,这是一个正数,但转换成有符号的int32时,由于超出了有符号数的取值范围,会转换成一个负数,说明id2的数据要新。
1.2.4 空闲空间管理
PostgreSQL的MVCC机制中,更新和删除操作并不是对原有的数据空间进行操作,而是通过对元组(tuple)的多版本形式来实现的。而由此引发了过期数据的问题,即当一个版本的元组对所有事物都不可见时,那么它就是过期的,此时它占用的空间是可以被释放的。
上述过期空间的释放工作是交给VACCUM来进行的。在这个过程中,VACCUM会将数据页上的过期元组的空间标记为可用,而当有新的数据插入时,也会优先使用这些可用空间。因此如何将这些可用空间管理起来,并在需要的时候能够高效地分配出去是一个需要解决的问题。
当插入新行时,如果多个数据块中都有空闲空间,应把数据行插到哪个有空闲空间的数据块中呢?
首先,有空闲空间的数据块不一定能容纳下新的数据行,所以要插入一行数据时,首先要快速找到一个数据块,且此数据块中的空闲空间能够放下此数据行。 要完成这一操作,要实现以下两个功能:
- 要记录每个数据块空闲空间的大小。
- 查找时,不能一个一个地找,要实现快速查找
Postgresql引入了FSM(Free Space Map)结构来管理数据页中的空闲空间。FSM是存在以_fsm为后缀的文件中的,每个表都有一个对应的fsm文件。
FSM的存在的意义就是为了管理空闲资源,并且让它们可以快速地被再次使用,所以结构的设计要以小而快的目标。FSM的空间管理中,没有细粒度到数据页的每个比特.为缩小FSM文件的大小,只使用一个字节来记录一个数据块中的空闲。即将最小单元定义为页大小(BLCKSZ)的256分之一,也就是说,在默认8KB数据页的大小下,从FSM的角度观察,它有256(2^8)个单元。
从PostgreSQL 8.4版本之后,对每个数据文件创建一个名为“<表oid>_fsm”的文件,如假设一个表“test01”的OID为“25566”,则它的FSM文件名为“25566_fsm”。
为了快速查找到满足要求的数据块,PostgreSQL使用了树型结构组织FSM文件,FSM中将每个页的空余空间信息通过一个大根堆的形式组织的, 想要知道是否有满足需求的空间,只需要从堆的根获取到当前最大的空余空间就可以快速的判断,减少了整体的判断次数,提高效率 。其结构如下:
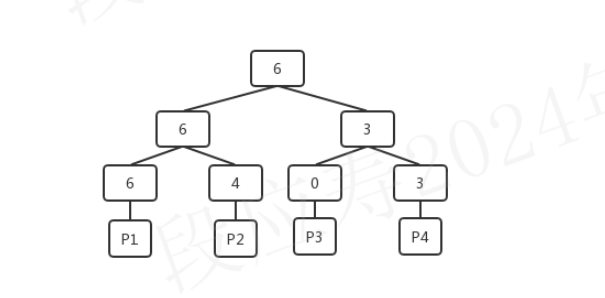
堆中的每个叶子节点都对应一个数据页,叶子节点上记录的是数据页的可用单元的个数,例如,上图中P1中当前包含了6个空闲单元。每个非叶子节点上的记录的则是它的子节点中较大的可用数目。
FSM文件固定使用3层树型结构,第0层和第1层为查找辅助层,第2层中每个块的每个字节代表其对应的数据块中的空闲空间。fsm示意图如下(实际的fsm块每层由多个):
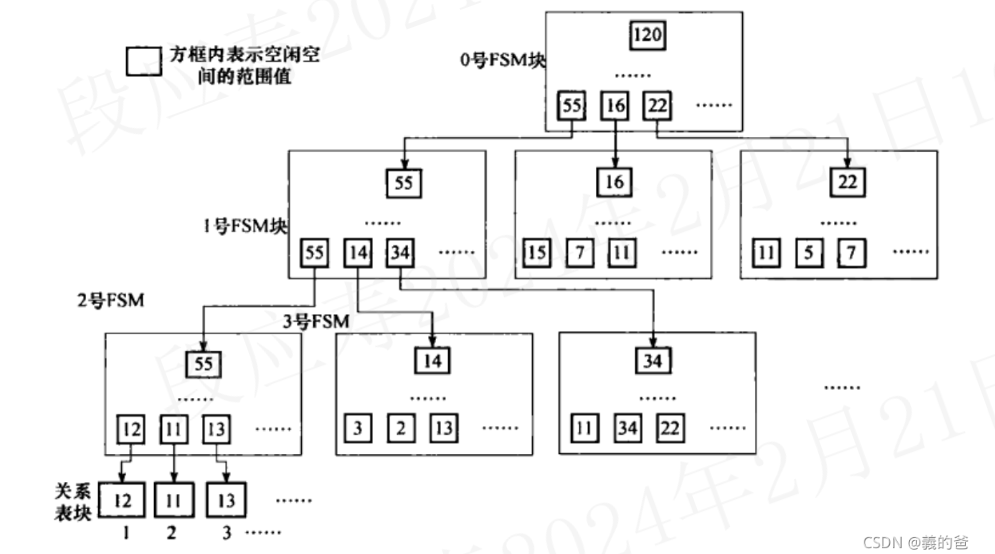
为什么fsm的文件大小一般是24KB?
fsm实际在文件中也是按页存储的,即每一层二叉树用一页存储,因为这里用的是3层二叉树,所以需要3个页,如果默认页大小BLCKSZ是8KB,那么fsm文件的大小就是24KB。
[root@node1 13458]# ls -alh 16384*
-rw------- 1 polkitd input 8.0K 2月 20 16:41 16384
-rw------- 1 polkitd input 24K 2月 20 16:41 16384_fsm
-rw------- 1 polkitd input 8.0K 2月 20 16:41 16384_vm
为什么fsm只需要3层二叉树?
fsm实际在文件中也是按页存储的,对于BLCKSZ是8KB的场景,每个二叉树可以大约存储81024/2个二叉树叶子节点,即4000个左右。三层二叉树共可以存储4000^3=(2^22^10)^3=2^36个数据页。 我们知道,Postgresql中每张表最多有2^32-1个数据页,因而三层二叉树即可满足。
按照前文所述,fsm使用1个字节来表示一个数据块,一个字节可以取值0~255共256个单元,若BLCKSZ为8KB,则每个单元表示32字节空闲空间。
Postgresql提供了一个插件pg_freespacemap可供我们查询FSM,该插件提供了一种方法来检查空闲空间映射(FSM)。
它提供了一个称为pg_freespace的函数,或者准确地说是两个重载的函数。这些函数显示空闲空间映射中为一个给定页面所记录的值,或者显示关系中所有页面的记录值。
postgres=# create extension pg_freespacemap;
CREATE EXTENSION
postgres=# select * from pg_freespace('test');
blkno | avail
-------+-------
0 | 8064
(1 行记录)
postgres=#
1.2.5 可见性映射表文件
在PostgreSQL中更新、删除行后,数据行并不会马上从数据块中被清理掉,而是需要等VACUUM时清理。为了能加快VACUUM清理的速度并降低对系统I/O性能的影响,PostgreSQL在8.4.1版本之后为每个数据文件加了一个后缀为“_vm”的文件,此文件被称为可见性映射表文件,简称VM文件。VM文件中为每个数据块存储了一个标志位,用来标记数据块中是否存在需要清理的行。有该文件后,做VACUUM扫描此文件时,如果发现VM文件中该数据块上的位表示该数据块没有需要清理的行,VACUUM就可以跳过对这个数据块的扫描,从而加快VACUUM清理的速度。
VACUUM有两种方式,一种被称为“Lazy VACUUM”,另一种被称为“Full VACUUM”,VM文件仅在Lazy VACUUM中使用,Full VACUUM操作则需要对整个数据文件进行扫描。
1.2.6 reference
- https://blog.csdn.net/weixin_39540651/article/details/119139620
- https://zhuanlan.zhihu.com/p/67725967
- https://www.cnblogs.com/mingfan/p/14771267.html
- http://mysql.taobao.org/monthly/2019/03/06/
- https://blog.csdn.net/weixin_45644897/article/details/120691227
- https://wiki.postgresql.org/images/8/81/FSM_and_Visibility_Map.pdf
- https://www.eggtart.icu/learning/posgresql-fsm/
1.2 控制文件
PostgreSQL的控制文件记录了数据库的重要信息,如数据库的系统标识符“system_identifier”、系统表版本“Catalog version number”、实例状态、Checkpoint信息、数据页的块大小、WAL日志的页大小及文件大小、一些实例备份和恢复信息等。
在PostgreSQL中提供了pg_controldata命令显示控制文件中的内容:
root@1db814f27ee9:/# pg_controldata /var/lib/postgresql/data
pg_control version number: 1201
Catalog version number: 201909212
Database system identifier: 7337595217489322023
Database cluster state: in production
pg_control last modified: Wed 21 Feb 2024 06:27:26 AM UTC
Latest checkpoint location: 0/16AFEB0
Latest checkpoint's REDO location: 0/16AFE78
Latest checkpoint's REDO WAL file: 000000010000000000000001
Latest checkpoint's TimeLineID: 1
Latest checkpoint's PrevTimeLineID: 1
Latest checkpoint's full_page_writes: on
Latest checkpoint's NextXID: 0:496
Latest checkpoint's NextOID: 24576
Latest checkpoint's NextMultiXactId: 1
Latest checkpoint's NextMultiOffset: 0
Latest checkpoint's oldestXID: 480
Latest checkpoint's oldestXID's DB: 1
Latest checkpoint's oldestActiveXID: 496
Latest checkpoint's oldestMultiXid: 1
Latest checkpoint's oldestMulti's DB: 1
Latest checkpoint's oldestCommitTsXid:0
Latest checkpoint's newestCommitTsXid:0
Time of latest checkpoint: Wed 21 Feb 2024 06:27:24 AM UTC
Fake LSN counter for unlogged rels: 0/3E8
Minimum recovery ending location: 0/0
Min recovery ending loc's timeline: 0
Backup start location: 0/0
Backup end location: 0/0
End-of-backup record required: no
wal_level setting: replica
wal_log_hints setting: off
max_connections setting: 100
max_worker_processes setting: 8
max_wal_senders setting: 10
max_prepared_xacts setting: 0
max_locks_per_xact setting: 64
track_commit_timestamp setting: off
Maximum data alignment: 8
Database block size: 8192
Blocks per segment of large relation: 131072
WAL block size: 8192
Bytes per WAL segment: 16777216
Maximum length of identifiers: 64
Maximum columns in an index: 32
Maximum size of a TOAST chunk: 1996
Size of a large-object chunk: 2048
Date/time type storage: 64-bit integers
Float4 argument passing: by value
Float8 argument passing: by value
Data page checksum version: 0
Mock authentication nonce: 8242cbd9ab9f94ca6eec380df819fa397c0b2fd6bdbd64e76d3df8cd9bff5504
root@1db814f27ee9:/#
1.2.1 数据库唯一标识
数据库的唯一标识串“Database system identifier”用于唯一标识一套数据库系统,流复制的主数据库和备数据库有相同的数据库唯一标识串。在备库和主库建立流复制关系时需要根据该标识来确认是否能建立流复制关系,如果数据库唯一标识不同,将无法建立流复制关系。
数据库的唯一标识串是在Initdb初始化数据库实例时生成的,它是一个64bit的整数。该整数由当前的时间戳和执行Initdb进程的PID的两个部分组成,如果知道了PostgreSQL数据库的唯一标识串,就能知道该数据库是什么时候创建的。
postgres=# SELECT to_timestamp(((7337595217489322023>>32) & (2^32 -1)::bigint));
to_timestamp
------------------------
2024-02-20 08:16:57+00
(1 行记录)
postgres=#
1.2.2 checkpoint信息
Postgresql采用WAL日志来保证数据一致性,优先保证WAL日志写入磁盘。当数据库宕机时,可以通过重放wal日志来恢复数据库。但wal日志重放存在如下问题:
- WAL重做日志不可以无限增大,因为WAL日志会占用一定的空间。
- 重放WAL日志会占用时间,不可能一个数据库宕机后我们花费很长时间来进行恢复,通常需要在有限的时间内完成恢复,如在几分钟之内完成。
- 缓冲区不可能无限大,所以不管怎么样,都需要把一定的脏数据刷新到磁盘中,需要考虑必须要先刷新哪些脏数据等问题。
为解决以上问题,Postgresql提供了检查点机制。检查点只是一个数据库事件,该事件触发后将会执行一个操作,而此操作可以保证把事件之前的脏数据全部刷新到磁盘中。Checkpoint发生得越频繁,在数据库实例宕机后重放的WAL日志量就越少,当然重做的日志量的多少也取决于发生宕机的时间点,发生宕机的时间点越靠近最后的检查点,重做的日志量也就越少。
Postgresql的控制文件中存放了checkpoint的相关信息,其内容如下:
Latest checkpoint location: 0/16AFEB0
Latest checkpoint's REDO location: 0/16AFE78
Latest checkpoint's REDO WAL file: 000000010000000000000001
Latest checkpoint's TimeLineID: 1
Latest checkpoint's PrevTimeLineID: 1
Latest checkpoint's full_page_writes: on
Latest checkpoint's NextXID: 0:496
Latest checkpoint's NextOID: 24576
Latest checkpoint's NextMultiXactId: 1
Latest checkpoint's NextMultiOffset: 0
Latest checkpoint's oldestXID: 480
Latest checkpoint's oldestXID's DB: 1
Latest checkpoint's oldestActiveXID: 496
Latest checkpoint's oldestMultiXid: 1
Latest checkpoint's oldestMulti's DB: 1
Latest checkpoint's oldestCommitTsXid:0
Latest checkpoint's newestCommitTsXid:0
“Latest checkpoint location”和“Prior checkpoint location”这两项指的是“最后一次的Checkpoint位置”和“前一次的Checkpoint位置”。
虽然Checkpoint事件是一个时间点,但执行Checkpoint刷盘的操作是需要进行一段时间的,如现在我们要开始做Checkpoint了,先记录当前点,该当前点就记录在“Latest checkpoint's REDO location”中,当完成刷盘操作之后,把Checkpoint相关信息也生成一条WAL记录,再把这条WAL记录也写入WAL日志文件中,此WAL日志的位置就是“Latest checkpoint location”,然后更新控制文件中有关Checkpoint的信息。
checkpoint写入wal日志的流程如下:
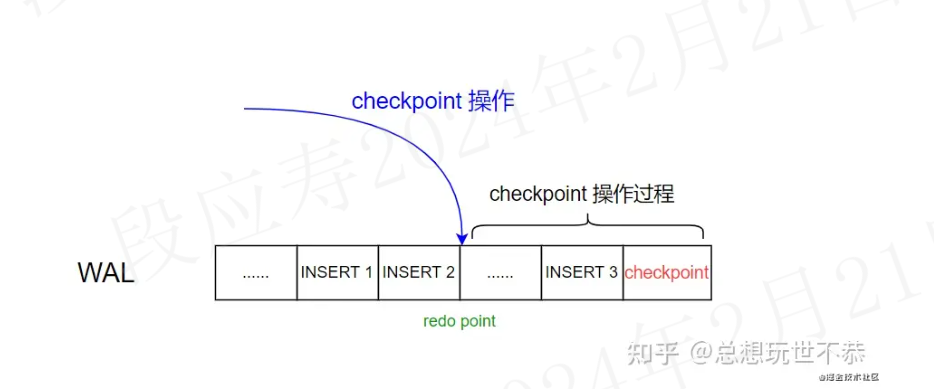
- checkpoint 操作首先记录下 checkpoint 的开始位置,记录为 Latest checkpoint's REDO location(重做位点)
- checkpoint 将 shared buffer 中的数据刷到磁盘里面去
- 这时候数据库又来了一条 SQL insert 3
- checkpoint 刷脏结束,redo point 之前的数据均已被刷到磁盘存储(数据1和2)
- 这时候在 WAL 日志里面记录 checkpoint 位点(红色),表明 checkpoint 操作结束。checkpoint 位点会记录相关信息,比如 redo point 的值(从哪开始重做)(checkpoint本身也会生成一条wal日志记录。) ,此时的checkpoint位置记录为Latest checkpoint location
- 将最新的 checkpoint 位点记录在 pg_control 文件中
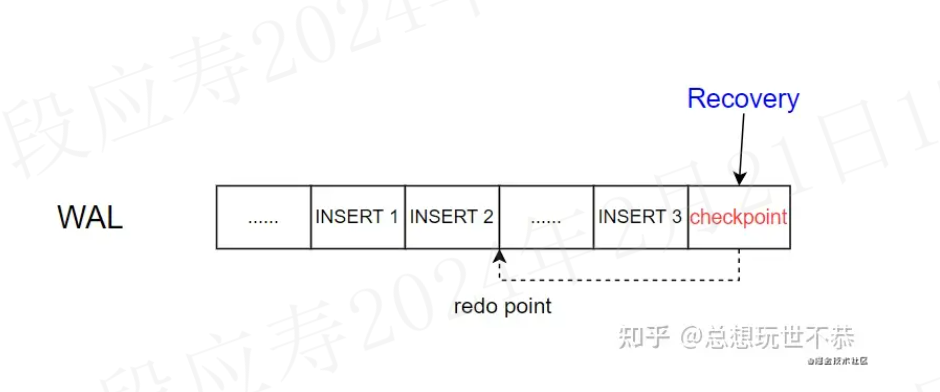
根据checkpoint恢复的流程如下:
- 从 pg_control 文件中找到最新的 checkpoint 位置
- 从 checkpoint 找到 redo point 的位置,开始重放日志
1.2.3 备库相关信息
备库的控制信息与主库并不完全相同,主要体现在如下两个字段不一致。
主库中这两项都是0。
Minimum recovery ending location: 0/0
Min recovery ending loc's timeline: 0
备库中这两项均不为0,
Minimum recovery ending location: 0/50004F0
Min recovery ending loc's timeline: 1
备库在不停地应用WAL日志,对于Hot Standby,在应用WAL日志的同时,还会对外提供服务。
备库本身也可能因断电或其他故障而宕机,当备库在重新启动时,不能一启动就对外提供只读服务,因为这时的数据可能还不一致,如果这时提供只读服务,用户会读到不一致的数据。
这两个参数用于指定当备库异常终止再启动时,只有应用WAL日志超过指定点之后才能对外提供只读服务。
为什么在主库上不需要这两项内容呢?
因为在主库上,只有把当前所有的WAL日志全部应用完成之后才能对外提供服务,而备库是不断地从主库接收日志,然后不断地应用日志,没有把当前WAL日志应用完的说法,所以在备库上需要知道应用多少日志之后就可以对外提供只读服务了。
reference
1.3 WAL文件
1.3.1 关键概念
- wal:WAL文件是“Write Ahead Log”的简称,就是数据库重做日志,与Oracle的Redo Log的功能是一样的。
root@eb2e0ae36696:/var/lib/postgresql/data# ls pg_wal/ -alh
total 49M
drwx------ 3 postgres postgres 124 Feb 21 08:59 .
drwx------ 19 postgres root 4.0K Feb 21 09:07 ..
-rw------- 1 postgres postgres 16M Feb 21 09:12 000000010000000000000005
-rw------- 1 postgres postgres 16M Feb 21 08:54 000000010000000000000006
-rw------- 1 postgres postgres 16M Feb 21 08:54 000000010000000000000007
drwx------ 2 postgres postgres 6 Feb 20 08:16 archive_status
- LSN:“Log Sequence Number(日志序列号)”,是一个不断增长的8字节(64bit)长数字,用于记录WAL日志的绝对位置,随着数据库WAL日志的不断增加,LSN也会不断地增长。
1.3.2 wal文件构成
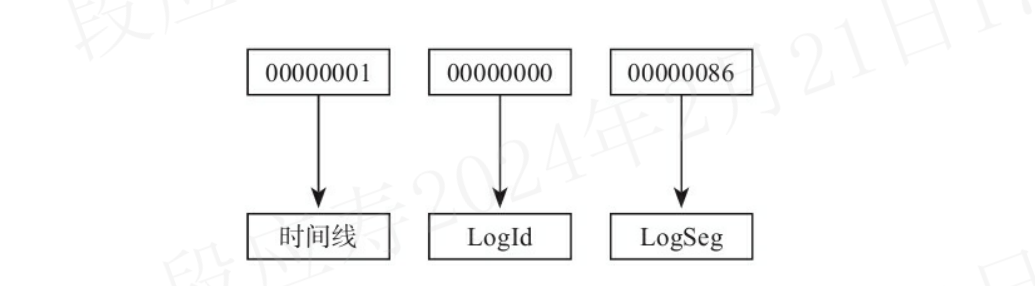
WAL文件名的24个字符由三部分组成:
- 时间线:英文为timeline,是以1开始的递增数字,如1,2,3,…
- LogId:32bit长的一个数字,是以0开始递增的,如0,1,2,3,…。实际为LSN的高32bit
- LogSeg:32bit长的一个数字,是以0开始递增的,如0,1,2,3,…。LogSeg是LSN的低32bit的值再除以WAL文件大小(通常为16MB)的结果。注意:当LogId为0时,LogSeg是从1开始的。
WAL日志文件默认大小为16MB,如果想改变其大小,在PostgreSQL10.X及之前的版本中需要重新编译程序,在PostgreSQL11.X版本之后,可以在Initdb初始化数据库实例时指定WAL文件的大小。 如果WAL文件是默认大小,即16MB时,LogSeg最大为FF,即000000~0000FF,即在文件名中,最后8字节中前6字节总是0。这时因为LSN的低32bit的值再除以WAL文件大小[2^32/(1610241024)=256]最大只能是256,换算成十六进制,即FF。
1.3.3 wal文件循环复用
PostgreSQL的循环覆盖写是通过把旧的WAL日志“重命名”来实现的。发生一次Checkpoint之后,此Checkpoint点之前的WAL日志文件都可以删除,而PostgreSQL中一般并不会将其删除,而是“重命名”旧的WAL文件使之成为一个新的WAL文件。所以WAL文件目录下文件序号最大的那个WAL文件并不是当前正在写的WAL文件,因为这个WAL文件有可能是前一次Checkpoint时重命名旧文件产生的。
PostgreSQL在源代码中的“改名”方法实际上并不是用改名的方法实现的,而是用先创建一个新硬链接文件指向旧文件,然后再删除旧文件的方法。 硬链接不占用额外的存储空间,因为它们只是指向同一文件的不同名称,可以使用不同的名称来引用同一个文件,而无需创建该文件的多个副本。
1.3.4 wal日志归档
由于wal日志回收和循环复用的关系,以及备份还原的需要,一般需要对wal日志进行归档。wal日志归档不是默认开启的功能,需要配置归档命令,将wal日志从pg_wal目录下拷贝到非data目录下。
如下几种情况会触发wal日志归档:
- 手动切换wal日志
select pg_switch_wal();
- wal日志写满后触发归档
- 设置archive_timeout
1.4 clog文件
1.4.1 clog文件简介
PostgreSQL把事务状态记录在CommitLog中。PostgreSQL 9.X及之前版本中CLOG文件在数据目录的pg_clog子目录下,从PostgreSQL10版本开始,CLOG文件是在pg_xact子目录下。
事务的状态有以下4种。
- TRANSACTION_STATUS_IN_PROGRESS=0x00:表示事务正在进行中。
- TRANSACTION_STATUS_COMMITTED=0x01:表示事务已提交。
- TRANSACTION_STATUS_ABORTED=0x02:表示事务已回滚。
- TRANSACTION_STATUS_SUB_COMMITTED=0x03:表示子事务已提交。
CommitLog文件是一个位图文件,因为事务有上述4种状态,所以需要用两位来表示一个事务的状态。
Postgresql对clog进行了如下优化:
- PostgreSQL对CommitLog文件进行了Cache,即在共享内存中有clog buffer,所以多数情况下不需要读取CommitLog文件
- 在每行上有一个标志字段“t_infomask”,如果标志位“HEAP_XMIN_COMMITTED”被设置,就知道xmin代表的事务已提交,则不需要到CommitLog文件中去判断。同样,如果“HEAP_XMAX_COMMITTED”被设置,就知道xmin代表的事务已提交,则不需要到CommitLog文件中去判断。
2 Postgresql索引
2.1 索引简介
索引是数据库中的一种快速查询数据的方法。索引中记录了表中的一列或多列值与其物理位置之间的对应关系,就好比是一本书前面的目录,通过目录中页码就能快速定位到我们需要查询的内容。
建立索引的好处是加快对表中记录的查找或排序。但建索引要付出以下代价:
- 增加了数据库的存储空间
- 在插入和修改数据时要花费较多的时间,因为索引也要随之更新
除有加快查询的作用外,索引还有一些其他的用途,如唯一索引还可以起到唯一约束的作用。
2.2 索引的分类
- BTree:最常用的索引,BTree索引适合用于处理等值查询和范围查询
- HASH:只能处理简单的等值查询。
- GiST:
不是单独一种索引类型,而是一种架构,可以在这种架构上实现很多不同的索引策略。GiST索引定义的特定操作符可以用于特定索引策略。PostgreSQL的标准发布中包含了用于二维几何数据类型的GiST操作符类,比如,一个图形包含另一个图形的操作符“@>”,一个图形在另一个图形的左边且没有重叠的操作符“<<”,等等。 - SP-GiST:
SP-GiST是“Space-Partitioned GiST”的缩写,即空间分区GiST索引。它是从PostgreSQL9.2版本开始提供的一种新索引类型,主要是通过一些新的索引算法来提高GiST索引在某种情况下的性能。 - GIN:
反转索引,可以处理包含多个键的值,如数组等。与GiST类似,GIN支持用户定义的索引策略,可通过定义GIN索引的特定操作符类型实现不同的功能。PostgreSQL的标准发布中包含了用于一维数组的GIN操作符类,比如,它支持包含操作符“@>”、被包含操作符“<@”、相等操作符“=”、重叠操作符“&&”,等等。
2.3 索引的创建
创建索引的命令如下所示:
postgres=# \h create index
命令: CREATE INDEX
描述: 建立新的索引
语法:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ 名称 ] ON 表名 [ USING 方法 ]
( { 列名称 | ( 表达式 ) } [ COLLATE 校对规则 ] [ 操作符类型的名称 ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ WITH ( 存储参数 = 值 [, ... ] ) ]
[ TABLESPACE 表空间的名称 ]
[ WHERE 述词 ]
postgres=#
一般,在创建索引的过程中会把表中的数据全部读一遍,该过程所用时间由表的大小决定,对于较大的表,可能会花费很久的时间。在创建索引的过程中,对表的查询可以正常常运行,但对表的增、删、改等操作需要等索引建完后才能进行,为此PostgreSQL提供了一种并发建索引的方法,并发创建索引不会影响表的增删改操作,这是通过在CREATE INDEX中加CONCURRENTLY选项来实现的。当该选项被启用时,PostgreSQL会执行表的两次扫描,因此该方法需要更长的时间来建索引。
2.4 索引的特性
2.4.1 表达式上的索引
如Oracle数据库一样,PostgreSQL也支持函数索引。实际上,PostgreSQL索引的键除了可以是一个函数外,还可以是从一个或多个字段计算出来的标量表达式。 表达式上的索引并不是在索引查找时进行表达式的计算,而是在插入或更新数据行时进行计算,因此在插入或更新时,表达式上的索引会慢一些。
2.4.2 部分索引
部分索引是只对一个表中的部分行进行的索引,是由一个条件表达式把这部分行筛选出来,该条件表达式被称为部分索引的谓词。
2.4.3 gist索引
GiST是Generalized Search Trees的缩写,意思是通用搜索树。它是一种平衡树结构的访问方法,是用户建立自定义索引的基础模版,用户只要按模板实现所要求的GiST操作类中的一系列的回调函数就可以实现自定义的索引,而不用关心GiST索引具体是如何存储的。BTree和许多其他的索引都可以用GiST来实现。
通常,实现一种新的索引访问方法意味着大量的非常有难度的开发工作,如必须理解PostgreSQL的内部工作机制、锁的机制和WAL日志等,而GiST实现了一个高级的编程接口,只要求实现者实现被访问的数据类型的一些回调函数,而GiST框架层本身会处理并发、WAL日志和搜索树结构处理的任务,这样大大降低了开发一种新索引访问方式的难度。
PostgreSQL支持在任意数据类型上建立BTree索引,但是BTree索引只支持范围谓词(<,=,>),HASH索引仅支持相等查询,而GiST的索引还能支持包含(@>)、重叠(&&)等复杂运算。
要实现一个自定义的GiST索引操作类,需要实现GiST索引操作类的7个必选函数和两个可选函数,这9个函数的说明如下(后两个是可选函数)。
- consistent:给出一个索引项p和一个查询q,该函数确定索引项是否与查询相容(consitent),也就是说,条件“indexed_column indexable_operator q”对于此索引项下的所有行是否都为真,这主要是为了测试是否需要扫描此索引节点下的子节点,如果返回为真,会返回一个recheck标志,表明这个条件是可能为真还是确定为真。如果recheck为“false”表示条件确定为真,反之,表示条件可能为真。
- union:表示如何在树中组合信息。将多个项联合成一个索引项。
- compress:如何把数据项转换成一种适合存储在索引页中的格式。
- decompress:compress的反向操作。
- penalty:返回一个值,用于表示把一个新节点插入到一个树叉上的代价(cost)。返回值应该是一个非负值,如果是负值则被当作0。
- picksplit:当一个索引列需要分裂时,该函数决定哪些节点需要留在原索引页中,哪些节点需要移到新的索引页中。
- same:判断两个索引项是否相等,相等则返回true,否则返回false。
- distance:返回索引项p和查询值q之间的“距离”。
- fetch:将一个压缩过的索引数据项转换成原始的数据项。
contrib下的以下模块也提供了一些类型的GiST索引的操作类。
- btree_gist:使用GiST实现的BTree。
- cube:多维的cube类型。
- hstore:一种key/value存储类型。
- intarray:一维int4数据的RD-Tree实现。
- ltree:树型结构的索引。
- pg_trgm:文件相似性的索引。
- seg:浮点范围类型的索引。
2.4.4 SP-GiST索引
SP-GiST是“Space-Partitioned GiST”的缩写,即空间分区GiST索引。它是从PostgreSQL 9.2版本开始提供的一种新索引类型,主要是通过一些新的索引算法提高GiST索引在某种情况下的性能。它与GiST索引一样,是一个通用的索引框架,基于此框架可以开发自定义的空间分区索引。
要实现一个自定义的SP-GiST索引操作类,需要实现以下5个用户自定义函数。
- config:返回索引实现中的一些静态信息,如前缀的数据类型的OID、节点label的数据类型的OID等。
- choose:选择如何把新的值插入到索引内部tuple中的方法。
- picksplit:决定如何在一些叶子tuple上创建一个新的内部tuple。
- inner_consistent:在树的搜索过程中返回一系列的节点(树叉上的)。
- leaf_consistent:如果一个叶子节点满足查询则返回真。
2.4.5 GIN索引
GIN索引是Generalized Inverted Index的缩写,即广义倒排索引。通常GIN索引作为全文检索使用,即在文章中搜索指定的词。GIN索引中存储了一系列“key,位置列表”对,位置列表中存储了包含此key值的行的列表。同一行的rowid会出现在多个位置列表中。
与GiST索引一样,GIN索引也是一个通用的索引框架,基于此框架可以开发自定义的GIN索引。 要实现一个自定义的GIN索引操作类,需要实现以下两个用户自定义函数。
- extractValue:给定一个要被索引的项,返回一个key值的数组。
- extractQuery:给定一个要被查询的值,返回一个键的数组。
2.4.6 BRIN索引
BRIN表示块范围索引。BRIN是为处理这样的表而设计的:表的规模非常大,并且其中某些列与它们在表中的物理位置存在某种自然关联。一个块范围是一组在表中物理上相邻的页面,对于每一个块范围在索引中存储了一些摘要信息。
postgresql 按照一定的数目(默认 128, 可以通过 pages_per_range 指定),将相邻的数据 Block 分成一组,然后计算它的的取值范围。当需要查看数据时,会先遍历这些取值范围。当要查找的数据不在此范围内,则可以直接跳过这些数据 Block。
当数据按照一定规则新增时,比如监控数据,数据的查找会非常高效。而且块级索引的空间占用会很小,多个相邻的Block才会对应一条索引记录。
如果数据排列的比较随机时,那么索引效果就非常差,因为它起不到快速筛除不符合的数据 Block。造成数据排列乱的原因,还有频繁的删除数据,因为 postgresql 会将删除空间回收掉,后续的数据新增都会填补这些空间。虽然可以配置删除的数据不会回收,但是会造成存储空间浪费,所以块级索引还不适合频繁删除数据的场景。
2.5 reference
3 Postgresql系统优化
3.1 优化准则
- 第一种思路:有人说过,“The fastest way to do something is don't do it”,意思是说,“ 做得最快的方法就是不做”。从这个思路上来说,把一些无用的步骤或作用不大的步骤去掉就是一种优化。
- 第二种思路:做同样一件事情,要想更快有多种方法,最简单的方法就是换硬件,让数据库跑在更快的硬件上。但换硬件一般都是最后的选择,除此之外,最有效的方法是优化算法,如让SQL走到更优的执行计划上。
3.2 优化指标
在数据库优化中,主要有以下优化指标。
- 响应时间:衡量数据库系统与用户交互时多久能够发出响应。
- 吞吐量:衡量在单位时间内可以完成的数据库任务。
数据库优化工作中,第一项就是确定优化目标。
- 性能目标:如CPU利用率或IOPS需要降到多少。
- 响应时间:需要从多少毫秒降到多少毫秒。
- 吞吐量:每秒处理的SQL数或QPS需要提高到多少。
一个已运行的数据库系统,如果前期设计不合理、性能不高,后期在优化时会非常困难,有可能永远无法达到高性能,因此,在新建一套数据库系统前,首要的事应该是设计优化。良好的设计能最大限度地发挥系统的性能。
3.3 优化方法
优化的第一件事是确定目标,那么要如何确定一个合理的目标呢?这就需要使用测试工具。熟练使用常用的测试工具是做数据库优化的基础。下面是一些常用的测试工具。
- memtest86+:内存测试工具。
- STREAM:内存测试工具。
- sysbench:综合测试工具,可以测试CPU、I/O、数据库等。
- pgbench:PostgreSQL自带的测试工具,可以仿真TPC-B的测试模型。
- fio:最强大的免费I/O测试工具。
- orion:Oracle的I/O测试工具,测试裸设备的I/O能力,功能比fio要少,但使用简单。
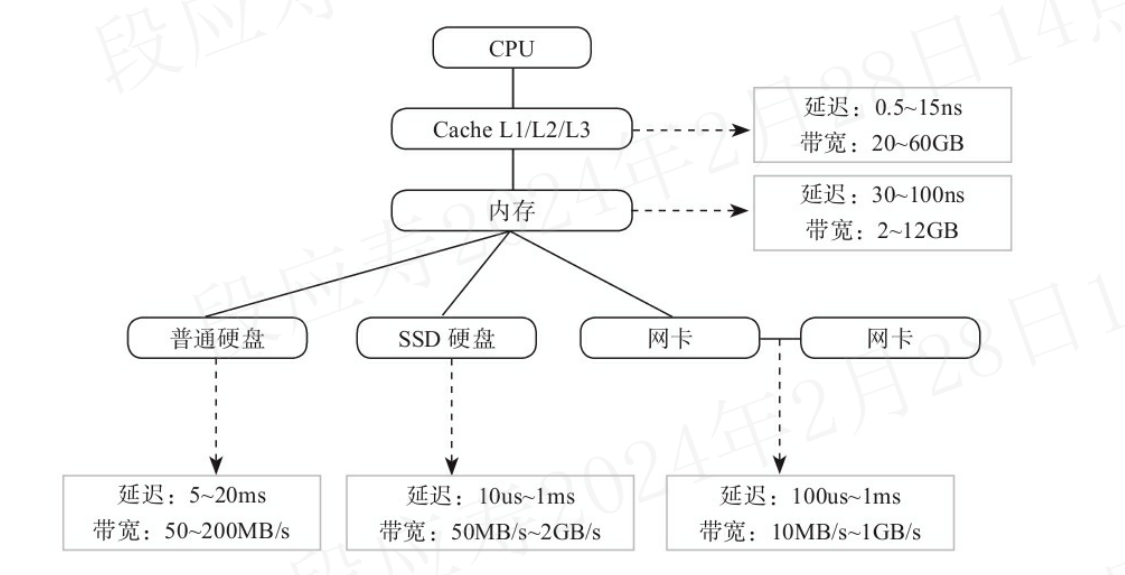
3.3.1 硬件知识
CPU、内存、网络、硬盘的响应时间和吞吐量都是不一样的,其响应时间和吞吐量如下图所示:
3.3.1.1 cpu及服务器体系结构
服务器系统可以分为以下几种体系结构。
- SMP/UMA -Symmetric Multi Processing/Uniform Memory Architecture
- 优点: 服务器中多CPU对称工作,无主次关系。各CPU共享相同的物理内存,访问内存任何地址所需的时间相同,因此程序设计较为简单。
- 缺点: 因多CPU无主次关系,需要解决内存访问冲突,所以硬件实现成本高
- NUMA-Non-Uniform Memory Access(numa)
- 优点:多CPU模块,每个CPU模块具有独立的本地内存(快),但访问其他CPU内存(慢),硬件实现成本低。
- 缺点:全局内存访问性能不一致;设计程序时需要特殊考虑
- MPP-Massive Parallel Processing
- 优点:由多个SMP服务器通过节点互联网络连接而成,每个节点都可访问本地资源(内存、存储等),完全无共享(Share-Nothing)。最易扩展,软件层面即可实现。
- 缺点:数据重分布;程序设计复杂
目前,Intel的X86架构属于NUMA架构,kunpeng920 也属于numa架构。Intel的Nehalem的架构如下图所示:
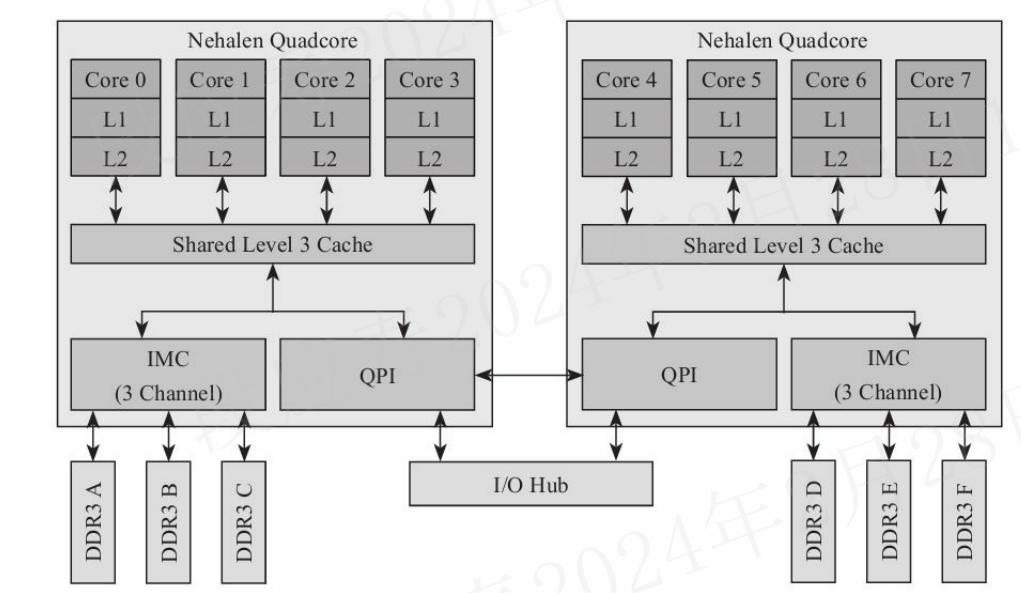
两颗4核的CPU通过总线连接,内存分别连接到各自的CPU上。所以从一个CPU的内存访问挂在另一个CPU上的内存,速度会慢一些。
- 主频:CPU的时钟频率,内核工作的时钟频率。
- 外频:系统总线的工作频率。
- 倍频:CPU外频与主频相差的倍数。
- 前端总线:将CPU连接到北桥芯片的总线。
- 总线频率:与外频相同,或者是外频的倍数。
- 总线数据带宽:(总线频率×数据位宽)/8
Intel CPU有以下3级cache。
- L1、L2级cache:核心core独占;带宽为20~80GB/S;延时为1~5ns。
- L3级cache:核心core之间共享;带宽为10~20GB/S;延时为10ns。
Intel CPU通过QPI(QuickPath Interconnect技术)与其他CPU通信,QPI大约在20GB/s 。
3.3.1.2 内存
内存是CPU与外部沟通的桥梁。CPU运算时所需的数据都临时保存在内存中,计算机的所有程序也都运行在内存中,内存通常也用于硬盘等外部存储器的数据缓存。
内存从硬件上分为以下几种。
- SRAM:静态随机存储器。随机是指数据不是线性依次存储的,而是自由指定地址进行数据读写的。CPU的cache一般使用这种存储方式,特点是速度快但造价高,不能大规模使用。
- DRAM:动态随机存储器。动态是指存储阵列需要不断刷新来保证数据不丢失。造价比SRAM低得多,但速度也慢一些。
- SDRAM:同步动态随机存储器,同步是指工作时需要同步时钟,内部命令的发送与数据的传输都以它为基准。
- DDR SDRAM:双倍数据传输率的SDRAM,DDR是“Double Data Rate”的缩写。普通的SDRAM在一个时钟周期内只传输一次数据,即它在时钟的上升期进行数据传输;而DDR内存则在一个时钟周期的上升期和下降期各传输一次数据,因此称为双倍速率同步动态 随机存储器。DDR内存又分DDR1、DDR2、DDR3、DDR4几种,分别对应第一代、第二代、第三代、第四代DDR。目前主流的内存为DDR4内存。
可以使用如下命令查看内存条及其相关参数:
dmidecode -t memory
lshw -C memory
3.3.1.3 硬盘
硬盘按接口可以分为以下3种。
- ATA系列:包括较早的硬盘接口,比如IDE(Integrated Drive Electronics)、PATA(Parallel ATA)及SATA(Serial ATA)。
- SCSI系列:包括早期的并行SCSI和现在使用较广泛的SAS(串行SCSI)。
- FC接口:支持FC协议接口的硬盘。
FC接口的硬盘一般只在专用存储上使用,通常见到的硬盘都是SATA或SAS接口的。
硬盘按存储介质来区分,可以分为以下两种。
- HDD:普通机械硬盘。
- SSD:固态硬盘。
机械硬盘和SSD硬盘都有SATA和SAS接口的这两种。
硬盘通常通过SAS或SATA接口的卡连接到主机上。SAS卡既能接SAS硬盘,也能接SATA硬盘,但SATA卡只能接SATA硬盘。
目前SAS的接口速度一般是3Gb/s或6Gb/s。
目前在服务器上使用的硬盘其大小有以下三种:
- 2.5英寸。
- 3.5英寸。
- M.2。
当前SSD硬盘的大小一般是2.5英寸,当然现在的固态也可能是和内存条一般大小的一块芯片(m.2)。
3.3.1.4 机械硬盘
机械硬盘的存取速度一般和转速有关系,转速通常有以下几种:
- 7200转,目前大多数的SATA硬盘都是7200转。
- 10000转。
- 15000转。
转速的单位是转/分钟,也就是10000转的硬盘的转速实际是1分钟10000转。
机械硬盘通过如下性能指标来衡量:
- 平均寻道时间(E):15000转的SAS硬盘为4ms左右。
- 旋转延时(L):15000转的SAS硬盘为2ms左右。
- 内部传输时间(X):通常为0.8ms。
- 吞吐率(Throughput):15000转的SAS硬盘为170Mb/s左右,机械硬盘为50~200Mb/s。
- 磁盘服务时间:RS=E+L+X=6.8ms。
- 硬盘的IOPS:可以算出硬盘的IOPS=1/RS=1000ms/6.8=147。
3.3.1.5 固态硬盘
SSD硬盘一般分为如下两种。
- SLC:是“Single Layer Cell”的缩写,特点是成本高、容量小、速度快,约10万次擦写寿命。
- MLC:是“Multi-Level Cell”的缩写,特点是容量大、成本低,但速度慢,约1万次擦写寿命。
- TLC:是“Trinary-Level Cell”的缩写,特点是容量最大、成本最低,但速度最慢,约1000次擦写寿命。
目前因为价格的原因,SLC的SSD基本看不到了,大都是MLC和TLC的SSD。
服务器上使用的SSD硬盘的性能指标如下。
- IOPS:读通常可以达到几万以上,写通常在几千以上。
- 吞吐率:读通常可以达到250Mb/s以上,写通常可以达到150Mb/s以上。
- 响应时间(Latency):读在几十微秒到100微秒之间,写在200微秒到1毫秒之间。擦除时间在2毫秒左右。
SSD硬盘与机械硬盘最大的差别有以下几点:
- SSD的随机性能好。SSD的读IOPS通常在机械硬盘的两个数据级以上,写IOPS也至少是1个数量级以上。但读写吞吐率一般只有机械硬盘的数倍,最多10倍左右。
- SSD内部存在擦除。也就是在重写旧数据时,不能像机械硬盘一样直接改写,而是需要经过一个擦除的过程后,才能再写。每次擦除的数据块比读写的块要大很多,通常在128KB到512KB之间,而读写的块大小通常为4KB。
- SSD中闪存芯片的写次数是有限的,写到一定次数时就会损坏。这个次数通常为10000~100000次。所以SSD内部需要一定的算法,让写比较平均地分散到其他各处。也就是说,如果一直写SSD硬盘的相同逻辑地址的同一个位置,实际写的物理芯片并不是同一个位置。
SSD硬盘内部通常有以下几种优化。
- FTL(Flash Translation Layer):物理逻辑地址映射。防止某个逻辑地址写太多次数而损坏芯片。
- Reclamation:异步擦除策略,降低延时。
- Wear Leveling:均衡写磨损,延长寿命。
- Spare Area:预留空间,减少写放大。一般情况下,SSD出厂后,内部会有一部分预留空间,而Intel的SSD用户还可以再多预留一部分空间,这样可以提高写性能。
3.3.2 文件系统及IO调优
目前PostgreSQL数据库还不支持直接在裸设备上存储数据,也就是说,PostgreSQL的数据必须存储在文件系统上,故而选择一个合适的文件系统对PostgreSQL数据库来说非常重要。
3.3.2.1 文件系统的崩溃恢复
文件系统中除记录文件内容信息外,还记录了一些元数据(如目录树、文件名、文件的块分配列表),以及和文件相关的一些属性(如文件名、文件的创建时间等),还有磁盘的空间分配信息(如哪些块已被分配、哪些块是空闲的)。
在写一个文件时,除了写文件的内容信息外,还会写一些元数据。为了保证数据的可靠性,在出现宕机等异常情况后,文件系统除了要保证元数据本身一致,还要求文件内容的数据与元数据之间也是一致的。 元数据一致性当然是最重要的,不能将同一个数据块分配给两个文件,这会导致一个文件的内容被另一个文件覆盖。分配出去的数据块必须有文件在使用,否则会导致明明现有文件并未占用多少空间,但文件系统上却没有空间了。当向一个文件的末尾添加数据时,文件会扩大,如果元数据记录了该文件的扩大,但新数据没有实际写入,就会导致新扩大的数据块中存在垃圾数据,这有可能导致问题产生。
早期的文件系统并不能保证元数据与数据的一致性,如Windows下的FAT文件系统和Ext2文件系统。当一个操作需要多次写元数据或一次写元数据一次写数据时,操作中的多个步骤通常不是原子性的,要保证一致性就必须要有类似数据库中的事务的概念。要有事 务就需要有日志,也就是说,要通过日志来保证整个操作的一致性。所以现在流行的文件系统都被设计成有日志的,如Ext3、Ext4及Windows下的NTFS文件系统。
但写日志相当于原先的一次写变成了两次写,可能会降低写的性能。为了降低对性能的影响,多数文件系统通常只是把元数据写入日志,而实际数据块内容的变更并不会写入日志。如果一个文件已被写过,再写以前的数据块时,不会分配新的数据块;关于空间分配的元数据也不会被更新,通常只更新文件上的时间戳。对于数据库来说,这种情况下通常不会产生不一致,所以数据库使用重写会更安全一些,PostgreSQL中WAL日志的写就是这样的。
3.3.2.1 Ext2文件系统
Ext2文件系统不是一种日志文件系统,它的性能比较好,但由于没有日志,在写数据时,如果机器突然宕机,文件系统中的数据可能会不一致。Ext2文件系统并不适合存放PostgreSQL的数据文件。
3.3.2.2 Ext3文件系统
Ext3文件系统是Linux下使用最广泛的文件系统,它提供以下3种数据日志记录方式。
- data=writeback:对数据不提供任何日志记录,只记录元数据的变更。所以元数据的写与数据块之间的写的先后顺序及多个数据块写的先后顺序都不能被保证。
- data=ordered:记录元数据,同时在逻辑上将元数据和数据块分组到被称为“事务”的单个单元中。将新的元数据写到磁盘上时,首先写的是相关的数据块,这样就保证了元数据与数据之间的一致性。但如果写一个数据块时出现宕机,有可能出现这个数据块只有一部分被写入,而另一部分还是旧数据的情况。
- data=journal:这种方式提供了完整的数据和元数据日志记录。对于所有新数据,首先写入日志,然后写入它的最终位置。在系统崩溃的情况下可以重放日志,使数据和元数据处于一致的状态。
实际操作时,指定日志记录方式的方法如下:
- 向/etc/fstab中与此文件系统相关的行中添加适当的字符串,如“data=journal”。
- 在调用mount时直接指定 -o data=journal命令行选项。
指定根文件系统的日志记录方式的方法稍有不同,需要在名为“rootflags”的特殊内核引导选项上进行设置,示例如下:
rootflags=data=journal
从理论上说,writeback模式的性能最好,但可靠性最差;journal模式的性能最差,但可靠性最好。如果硬件是带电池的Raid卡,而Raid卡上都有写缓存,在写缓存的帮助下,三者的性能差异并不是很大。因为文件系统日志的写通常是顺序写,这些顺序写的数据写入Raid卡的缓存中后会立即返回,而Raid卡会在后台再把数据刷新到磁盘中,所以这种情况下三种模式的性能差异并不大。 在PostgreSQL中通常会使用默认的ordered模式。当然也不应该完全放弃journal模式,因为journal模式提供了更全面的完整性保证。
3.3.2.3 Ext4文件系统
Ext4最有用的功能如下。
- 与Ext3兼容:只需执行一些命令就能将Ext3在线迁移到Ext4,而无须重新格式化磁盘或重新安装系统。原有的Ext3数据结构照样保留,Ext4将作用于新数据。
- 完善的barrier和fsync功能:Ext3在处理barrie和fsync功能时有一些问题,Ext4真正解决了这些问题,可以让PostgreSQL达到更高的磁盘吞吐量。这在大批量顺序读写时特别有用。
- 快速fsck:Ext3中执行fsck第一步就会很慢,因为它要检查所有的inode,现在Ext4给每个组的inode表中都添加了一份未使用inode的列表,在Ext4做fsck时就可以跳过这些未使用的inode节点。
- Extents:Ext3采用间接块映射,当操作大文件时,效率极其低下。比如一个100MB大小的文件,在Ext3中要建立25600项(每个数据块占用一项,数据块大小为4KB)的映射表;而Ext4引入了现代文件系统中流行的extent概念,每个extent为一组连续的数据块,对一个连续的空间,只需要一项就可以表示,这大大提高了效率。
- 多块分配:当写数据到Ext3文件系统中时,Ext3的数据块分配器每次只能分配一个4KB的块,写一个1GB文件就要调用256000次数据块分配器,而Ext4的多块分配器(Multiblock Allocator' MBAlloc)支持一次调用分配多个数据块。
- 延迟分配:Ext3的数据块分配策略是尽快分配,而Ext4和其他先进的文件系统一样,都是尽可能地延迟分配,直到文件在cache中写完才开始分配数据块并写入磁盘,这样就能让多块分配及extent的性能发挥到最佳。
- 在线碎片整理:尽管延迟分配、多块分配和extents能有效减少文件系统碎片,但碎片还是会不可避免地产生。Ext4支持在线碎片整理,并提供了e4defrag工具进行个别文件或整个文件系统的碎片整理。
- 日志校验:日志是最重要的部分,硬件原因也会导致日志损坏,而从损坏的日志中恢复数据会导致更多的数据损坏。Ext4的日志校验功能可以避免此问题。另外,Ext4将Ext3的两阶段日志机制合并成一个阶段,提高了性能。
- “无日志”(No Journaling)模式:Ext4允许完全关闭日志,以便某些有特殊需求的用户借此提升性能。
- 持久预分配(Persistent Preallocation):一些下载软件为了保证下载的文件有足够的空间存放,常常会预先创建一个与所下载文件大小相同的空文件,以免未来的数小时或数天之内磁盘空间不足导致下载失败。Ext4在文件系统层面实现了持久预分配的API函数,即libc中的posix_fallocate(),这种方式比用应用软件实现更高效。
- inode的新特性:Ext4支持更大的inode,Ext3默认的inode大小为128字节,Ext4默认的inode大小为256字节,这样就可以在inode中容纳更多的扩展属性,如纳秒时间戳或inode版本。Ext4还支持快速扩展属性(fast extended attributes)和inode保留(inodes reservation)。
- 更大的文件系统和更大的文件:Ext3目前最大支持16TB的文件系统和2TB的文件,Ext4则最大支持1EB(1048576TB,1EB=1024PB,1PB=1024TB)的文件系统以及16TB的文件。
- 无限数量的子目录:Ext3目前只支持32000个子目录,而Ext4支持无限数量的子目录。
3.3.2.4 XFS文件系统
XFS与前面讲的Ext3文件系统不同,它从一开始就设计为日志文件系统。从一些第三方的测试数据来看,在性能上,XFS相比Ext3有5%~30%的提高,所以建议在Linux环境下把PostgreSQL数据库建在XFS文件系统上。
3.3.2.5 Barriers I/O
为了保证数据的可靠性,I/O的写顺序很重要。例如,在PostgreSQL数据库中要求必须在写入WAL日志后,数据块的数据才能被写入。
在操作系统中,为了保证I/O的顺序,专门提供了一种I/O机制,被称为Barriers I/O。Barriers I/O定义如下:
- Barriers请求之前的所有在队列中的请求必须在Barries请求开始前被结束,并持久化 到非易失性介质中。
- Barriers请求之后的I/O需要等到其写入完成后才能执行。
Barries I/O是操作系统层面的概念,为了实现Barriers I/O,底层的硬件及驱动必须有相应的支持。SCSI/SAS硬盘通过FUA(Force Unit Access)技术和SYNCHRONIZE CACHE(同步缓存)技术来实现Barries I/O功能。
FUA技术让用户可以不使用硬盘上的缓存直接访问磁盘介质。SYNCHRONIZE CACHE技术让用户可以把整个硬盘上的缓存都刷新到 介质上。SATA硬盘可以通过FLUSH CACHE EXT调用来支持Barries I/O功能,另外,如果SATA硬盘开启了NCQ(Native Command Queuing),也可以处理FUA。
查看Linux是否装载了libata的方法如下:
(base) ➜ ~ dmesg |grep libata
[ 4.157767] libata version 3.00 loaded.
多数文件系统都提供了是否开启Barriers I/O选项,Ext3和Ext4默认开启了Barriers,如果想关闭Barriers,则需要在挂载文件系统时指定参数barriers=0,命令如下:
mount -o barriers=0 /dev/sdb1 /data/pgdata
XFS也默认打开了Barriers,如果想关闭,则需要在挂载文件系统时指定参数nobarrier ,命令如下:
mount -o nobarrier /dev/sdb1 /data/pgdata
3.3.2.5 I/O调优方法
3.3.2.5.1 打开noatime
每个文件上都有以下3个时间。
- ctime:改变时间。
- mtime:修改时间。
- atime:访问时间。 通常,PostgreSQL并不使用这3个时间,首先可以禁止atime,这样读文件时就不会再更新文件的atime。mtime和ctime有时还有些作用,如判断相应的数据文件最后是什么时候修改的。因此,PostgreSQL数据目录所在的文件系统在/etc/fstab中的配置项上一般都设置为“noatime”,示例如下:
/dev/sdd1 / xfs noatime,errors=remount-ro 0 1
3.3.2.5.2 调整预读
Linux环境下块设备通常都默认打开了预读,可以使用下面的命令查看预读的大小:
(base) ➜ ~ sudo blockdev --getra /dev/sda
256
(base) ➜ ~
上面的示例中返回值为“256”,表示是256个扇区,即128KB。
设置预读的命令如下:
blockdev --setra 4096 /dev/sda
设置并不会永久生效,机器重启后该设置就会失效,如果想让其永久生效,应该把上面的命令放到开始自启动脚本中,如放在/etc/rc.local中。
如果想让全表扫描更快,可以把预读调整得更大一些,如像上例中那样把预读设置为2MB。
3.3.2.5.3 调整虚拟内存参数
需要调整的第一个虚拟内存参数是swappiness,该参数值的范围为0~100,为0时表示尽量使用物理内存,取值越大,越倾向于使用SWAP空间,默认值为“60”。查看此参数当前值的方法如下:
(base) ➜ ~ cat /proc/sys/vm/swappiness
20
(base) ➜ ~
设置此参数值,并使其永久生效的方法是在/etc/sysctl.conf中添加如下命令行:
vm.swappiness = 0
然后执行如下命令,让/etc/sysctl.conf中的配置项生效:
sysctl -p
如果想让PostgreSQL数据库的性能尽量平稳,就应该把此值设置为“0”。
第二个需要调整的虚拟内存参数是“overcommit”。在Linux中,程序调用malloc()函数分配内存时,只分配虚拟内存,真正的物理内存并没有被分配,只有进程真正需要使用时才会分配物理内存。这种申请内存后并不会马上使用的技术就叫“Overcommit”技术。
Overcommit技术的优势在于,系统中运行的进程可以分配的内存数可以超过机器上拥有的物理内存,其劣势在于,当进程真正需要内存时,可能没有可用的物理内存可以使用,此时需把其他进程使用的内存放到SWAP区中,但是如果SWAP中也放不下,就会发 生OOM killer,它会选择杀死一些用户态的进程以释放内存。OOM的意思是“Out of Memroy”。
vm.overcommit参数可控制调用malloc()函数时分配内存的行为,此参数可以取以下3个值。
- 0:启发式策略,表示Linux将启发式地检查是否有足够的内存可以Overcommit,如果有则成功调用malloc(),内存申请成功;否则,内存申请失败,并把错误返回给应用程序。这种方式并不能完全避免OOM killer。
- 1:总是成功调用malloc(),并不管当前内存的实际情况。
- 2:不允许Overcommit,即当分配给所有进程的内存超过swapd大小+N%×物理时,会分配失败,N%是一个百分比,该值是由另一个参数vm.overcommit_ratio控制的。
上面参数值中的“0”和“1”都不能避免OOM killer,所以在PostgreSQL数据库中要把此参数设置为“2”,命令如下:
vm.overcommit_memory=2
要根据当前机器上的实际物理内存和SWAP空间的大小对参数vm.overcommit_ratio进行合理配置。如果想保守一些,让能分配的所有内存不超过物理内存的大小,如以下一台机器,其物理内存为4GB,SWAP也为4GB,则可以设置vm.overcommit_ratio为“0”,swap+0%*mem为“4G”,能分配的所有内存大小恰好是4GB:
vm.overcommit_ratio=0
另一台机器的内存为128GB,SWAP为4GB,则可以配置vm.overcommit_ratio为“95” ,这样能分配的所有内存为4G+128G×0.95=125.6GB,示例如下:
vm.overcommit_ratio=95
3.3.2.5.4 写缓存优化
在Linux系统中,对文件的普通写,并不会马上写入磁盘中,而是会先写到内存页cache中,实际刷新到磁盘中的操作是由内核线程来完成的。在Linux2.6中,内核线程为pdflush,在Linux3.0以上则为flush进程。既然是由Linux中的一个内核线程后台刷新到磁盘中的,那么当内存中累积多少脏数据或积累多长时间后刷新是有讲究的,如果刷新得太频繁会产生过多的I/O,因为同一个数据块,在刷新到磁盘之前可能被写了好几次,但不管写了几次,实际上只会写到磁盘一次。而如果刷新太慢,会占用太多的内存,当真正需要内存时,需要先把脏数据刷新到磁盘中以腾出内存空间,从而导致PostgreSQL数据库的性能出现较大的抖动。
在Linux系统中有以下3个参数用于控制写缓存的过程。
- vm.dirty_background_ratio:指定文件系统缓存脏页数量达到系统内存百分之多少时(如5%)触发内核刷脏页线程,并将缓存的脏页异步地刷入磁盘中。
- vm.dirty_ratio:指定当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不把缓存脏页写入磁盘中,此过程可能导致很多应用进程的文件I/O被阻塞。
- vm.dirty_writeback_centisecs:单位为百分之一秒,指定内核线程执行刷新脏页的回写操作之间的时间间隔。
在早期的Linux2.6的内核中,vm.dirty_background_ratio的值为“10”,而vm.dirty_ratio的值为“40”,这两个参数的值明显太大了,在较新的内核中,对这两个参数的默认值做了如下修改:
vm.dirty_background_ratio = 10
vm.dirty_ratio = 20
在较大内存的机器上还可以把这两个值调得更低一些,如在8GB以上的机器上可以做如下调整:
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
在实际应用中可以根据需求,通过测试来确定一个更精确的值。
3.3.2.5.5 调整IO调度器
Linux系统下通常有以下3种I/O调度器。
- cfq:完全公平队列(Completely Fair Queuing),尝试为所有的请求分配公平的I/O带宽,注意是带宽,而不是响应时间。
- deadline:平衡所有请求,避免某个请求被饿死,使响应时间最优化。
- noop:除了基本的块合并及排序工作以外,其他基本上什么也不做。
可以看出,数据库比较适合使用deadline调度器,而Linux下默认的I/O调度器是cfq。手动设置调度器的方法如下:
echo deadline > /sys/block/sdd/queue/scheduler
上面手动设置的方法并不持久,在机器重启后,设置就会失效。如果想将设置持久化,可以把上述命令行放到开机自启动脚本“rc.local”中。另一种方法是在Linux内核启动命令行上改变默认的I/O调度器,常用的修改的方法是修改grub.conf中的启动命令行,在命令行后加上“elevator=deadline”,命令如下:
kernel /vmlinuz-2.6.18-128.e15 ro root=/dev/sda1 elevator=deadline
实际上,改变I/O调度器对PostgreSQL性能的提升很小,所以保留默认的调度器也是可以的。
3.3.2.6 SSD的trim优化
当删除一个文件时,该文件在SSD内部占用的空间实际上是可以擦除的,但因为SSD内部并不了解文件系统的情况,这些可被擦除的空间仍然会被保留,这会使SSD变慢。而目前常用的文件系统(如Ext4、XFS)都提供了通知SSD哪些数据块可以被擦除的功能, 即文件系统向SSD发送了Trim指令。当然要使用该功能,需要在mount文件系统时加上discard选项,命令如下:
mount -o discard, noatime/dev/sdd1 /data
4 Postgresql主备切换
4.1 standby数据库原理
数据库服务器通常允许存在一个与主库同步的在线备数据库服务器,当主数据库服务器失败后,备数据库服务器可以快速提升为主服务器并提供服务,从而实现数据库服务的高可用;同时,备数据库服务器也提供了数据库的另一个副本,当主数据库服务器的数据丢失后,备数据库服务器上还有一份数据,不会导致数据的完全丢失,从而提高数据的可靠性。
另一种模式是允许多台数据库服务器同时提供负载均衡服务。因为数据库内部记录的是数据,当多台数据库同时提供服务时,不会像Web服务器那么简单,因为Web服务器是无状态的,而数据库是有状态的,主备数据库之间存在着数据同步,通常是一台主数据 库提供读写,然后把数据同步到另一台备数据库,这台备数据库不断应用(apply)从主数据库发来的变化数据。这台备数据库服务器不能提供写服务,通常最多提供只读服务。在PostgreSQL中能提供读写全功能的服务器称为Primary Database或Master Database,若备份数据库在接收主数据库同步数据和应用同步数据时不能提供只读服务,则该备份数据库称为Warm Standby Server;而如果备份数据库在接收和应用主数据库同步数据时也能提供只读服务,则该备份数据库称为Hot Standby Server。
4.1.1 PITR原理
PostgreSQL在数据目录的pg_wal子目录(10版本之前是pg_xlog子目录)中始终维护一个WAL日志文件。该日志文件记录了数据库数据文件的每次改变。最初设计该日志文件的主要目的是为了数据库异常崩溃后,能够通过重放最后一次Checkpoint点之后的日志文件,把数据库推到最终的一致状态,避免数据丢失或不一致。
当然,因为此日志文件的机制也提供了另一种热备份方案:先把数据库以文件系统的方式备份出来,同时把相应的WAL日志也备份出来。虽然直接复制数据库数据文件会导致复制出来的数据文件不一致,如复制的多个数据文件不是同一个时间点的文件。同时复制一个8KB的数据块时也存在数据不一致的情况:假设刚复制完前4KB个块,而数据库又写了整个8KB的数据块的内容,这时复制的这个数据块的前4KB块和后4KB块不是一个完整的8KB的数据块,从而导致不一致。但因为有了WAL日志,即使备份出来的数据块不一致,也可以重放备份开始后的WAL日志,把备份的内容推到一致状态。
当有WAL日志之后,备份数据库不再需要一个完美的一致性备份,备份中的任何非一致性数据都会被重放WAL日志文件的过程纠正,所以我们可以在备份数据库时通过简单的cp命令或tar等操作系统提供的备份文件的工具来实现数据库的在线备份。
使用简单的cp命令或其他命令把数据库在线复制出来的备份,称为基础备份,从基础备份操作开始之后产生的WAL日志和此基础备份构成了一个完整的备份。把基础备份恢到另一台机器,然后不停地从原始数据库机器上接收WAL日志,在新机器上持续重放 WAL日志,只要应用WAL日志足够快,该备数据库就会追上主数据库的变化,拥有当前主数据库的最新数据状态。这个新机器上的数据库被称为Standby数据库。当主数据库出现问题无法正常提供服务时,可以把Standby数据库打开提供服务,从而实现高可用。
把WAL日志传送到另一台机器上的方法有两种,一种是通过WAL归档日志方法;另一种是PostgreSQL 9.X版本开始提供的被称为流复制的方法。
4.1.2 wal日志归档
所谓把WAL日志归档,其实就是把在线的已写完的WAL日志复制出来。在PostgreSQL中配置归档的方法是在配置文件“postgresql.conf”中配置参数“archive_mode”和“archive_command”,archive_command的配置值是一个UNIX命令,此命令把WAL日志文档复制到其他地方,示例如下:
archive_mode = on
archive_command = 'cp %p /backup/pgarch/%f'
上面的命令中“archive_mode=on”表示打开归档备份,参数“archive_command”的配置值是一UNIX的cp命令,命令中的“%p”表示在线WAL日志文件的全路径名,“%f”表示不包括路径的WAL日志文件名。在实际执行备份时,PostgreSQL会把“%p”替换成实际的在线WAL日志文件的全路径名,并把“%f”替换成不包括路径的WAL日志名。
也可以使用操作系统命令scp把WAL日志复制到其他机器上,从而实现跨机器的归档日志备份,命令如下:
archive_mode = on
archive_command = 'scp %p postgres@192.168.1.100:/backup/pgarch/%f'
使用上面复制WAL文件的方式来同步主、备数据库之间的数据,会导致备库落后主库一个WAL日志文件,具体落后多长时间取决于主库上生成一个完整的WAL文件所需要的时间。
4.1.3 流复制
流复制是PostgreSQL从9.0版本开始提供的一种新的传递WAL日志的方法。使用流复制时,Primary数据库的WAL日志一产生,就会马上传递到Standby数据库。流复制传递日志的方式有两种,一种是异步方式;另一种是同步方式。
使用同步方式,则在Primary数据库提交事务时,一定会等到WAL日志传递到Standby数据库后才会返回,这样可以做到 Standby数据库接收到的WAL日志完全与Primary数据库同步,没有一点落后,当主备库切换时使用同步方式可以做到零数据丢失。 异步方式,则是事务提交后不必等日志传递到Standby数据库就即可返回,所以Standby数据库通常比Primary数据库落后一定的时间,落后时间的多少取决于网络延迟和备库的I/O能力。
4.1.4 standby数据库的运行原理
当PostgreSQL数据库异常中止后,数据库刚重启时,会重放停机前最后一个Checkpoint点之后的WAL日志,把数据库恢复到停机时的状态,恢复完成后自动进入正常的状态,可以接收其他用户的查询和修改。
同步复制时,当备库出现问题后,通常会导致主库也会被hang住。PostgreSQL提供了多个Standby数据库的功能,如配置两个Standby数据库,当一个Standby数据库损坏时,主数据库不会被hang住,两个备数据库都出现问题时才会导致主数据库不能写。PostgreSQL 9.2版本开始,增加级连复制的功能,也就是一个Standby数据库后面可以再级连另一个Standby数据库,也就是说,其他Standby数据库不必都从主数据库上拉取WAL日志,可以从其他Standby数据库拉取WAL日志。
流复制协议不仅能传递WAL日志,也能传递数据文件,后面介绍的pg_basebackup工具就是通过流复制协议把远程主库的所有数据 文件传输到本地的。
PostgreSQL数据库是通过在数据目录下建一个特殊的文件来指示数据库启动在主库模式还是在备库模式,在PostgreSQL 12版本之前是通过文件“recovery.conf”来指示数据库启动在备库模式的(当然需要在recovery.conf中配置一些合适的内容才以),从PostgreSQL 12版本开始把recovery.conf中的配置项全部移到postgresql.conf配置文件中,不再使用recovery.conf文件。当然为了指示该数据库是备库,还需要在数据目录下建一个名为“standby.signal”的空文件。
如果我们在postgresql.conf中配置了“hot_standby”为“on”,说明备库是“Hot Standby”,即可以只读的,如果配置“hot_standby”为“off”,说明备库是“Warm Standby”,psql是无法连接这个备库的,连接时会报如下错误:
[postgres@pg01 ~]$ psql
psql: FATAL: the database system is starting up
4.1.5 创建standby备库的步骤
对于PostgreSQL 12版本的数据库,只需要在数据库的数据目录下建standby.signal文件,然后重新启动数据库,数据库就会进入Standby模式下。当然由于PostgreSQL 12版本中postgresql.conf的参数“hot_standby”是打开的,该数据库是只读的。对于PostgreSQL 12版本之前的数据库,如PostgreSQL 11版本,需要创建一个recovery.conf文件,并在文件中设置如下内容:
standby_mode = 'on'
当我们把文件standby.signal(如果是PostgreSQL 12之前的版本数据库是recovery.conf)删除,再重启数据库,数据库就变回主库了。
当然上面的步骤只是把主库转换成了备库,变成了只读库,并没有新建一个备库,通常我们需要新建一个只读备库,并从主库进行WAL日志的同步,最简单的方法是把主数据库停下来,把主数据库的数据目录原封不动地复制到备机,在备机数据库的数据目录下 建一个指示这个库是备库的文件(如果是PostgreSQL 12及以上版本是standby.signal文件,如果是PostgreSQL 12之前的版本是recovery.conf文件),然后在指定的配置文件(如果是在PostgreSQL 12及以上版本是postgresql.conf文件,如果是PostgreSQL 12之前的版本是recovery.conf文件)中配置如何连接主库的流复制,然后启动备库就完成了Standby备库的搭建。
上面这种通过冷备库的方式搭建备库的方式需要停止主库,如果数据库比较大,会有比较长的停库时间,这时会不方便,所以PostgreSQL也提供了热备份的方式搭建Standby备库,即在主库不停机,也不终止正常读写的情况下,就可以在线搭建Standby备库。
以热备份的方式建Standby备库的过程可分为以下两个大步骤。
- 第一步:通过在线热备份的方式生成一个基础备份,并把生成的基础备份传到备机上;
- 第二步:在备库上配置相关配置文件后,把备库启动在Standby模式下,这样就完成了Standby库的搭建。该步骤与冷备份搭建Standby备库的过程基本相同。
通过热备份的方式生成基础备份的方法有以下两种:
- 第一种是通过底层API的方式一步一步地完成。
- 第二种是通过pg_basebackup工具一键完成。
底层API的方式可以让我们更深入地了解热备份的原理,同时复制数据文件时可以使用更灵活的方式,如并发运行几个scp同时复制不同的数据文件,这样对于比较大的数据库可以更快地完成备库的搭建;使用pg_basebackup工具可以做到一键完成备库的搭建,这样会更方便。
底层API的方式搭建备库的过程和步骤如下:
- 以数据库超级用户身份连接到数据库,发出命令“SELECT pg_start_backup('label')”
- 执行备份:使用任何方便的文件系统工具,比如tar或cp直接把数据目录复制下来。操作过程中既不需要关闭数据库,也不需要停止对数据库的任何写操作。
- 再次以数据库超级用户身份连接数据库,然后发出命令“SELECT pg_stop_backup()” 。这将中止备份模式并自动切换到下一个WAL段。设置自动切换是为了在备份间隔中写入的最后一个WAL段文件可以立即为下次备份做好准备。
- 把备份过程中产生的WAL日志文件也复制到备机上
pg_start_backup()主要做了以下两项工作:
- 置写日志标志位:XLogCtl->Insert.forcePageWrites=true,也就是把这个标志设置为“t rue”后,数据库会把变化的整个数据块都记录到数据库中,而不仅仅是块中记录的变化
- 强制发生一次Checkpoint。
Standby数据库一直运行在恢复状态,如何让数据库运行在恢复状态呢?在PostgreSQL中是通过配置recovery.conf文件来实现的。在数据库启动过程中,如果发现数据目录($PGDATA环境变量指向的目录)下存在recovery.conf,就会按recovery.conf文件中指示的情况把数据库启动到恢复状态。
4.2 pg_basebackup命令行工具
4.2.1 pg_basebackup介绍
pg_basebackup工具把整个数据库实例的数据都物理地复制出来,而不是也不能只把数据库实例中的部分内容如某些表单独备份出来。
该工具使用流复制的协议连接到主数据库上,所以主数据库中的pg_hba.conf必须允许replication连接,也就是在pg_hba.conf中必须有如下形式的内容:
local replication osdba trust
local replication osdba ident
host replication osdba 0.0.0.0/0 md5
上例中第二列的数据库名填写的是“replication”,这并不是表示连接到名为“replication”的数据库上,而是表示允许这些客户端机器发起流复制连接。
理论上,一个数据库可以被几个pg_basebackup同时连接,但为了不影响主库的性能,建议最好还是一个数据库上同时只有一个pg_basebackup在它上面做备份。
PostgreSQL9.2之后支持级连复制,所以在9.2及以上的版本中pg_basebackup也可以从另一个Standby库上做基础备份,但从Standby备份时需要注意以下事项:
- 从Stamdby备份时不会创建备份历史文件(backup history file,即类似0000000100001234000055CD.007C9330.backup的文件)。
- 不确保所有需要的WAL文件都备份了,如果想确保,需要加命令行参数“-X stream”
- 在备份过程中,如果Standby被提升为主库,则备份会失败
- 要求主库中打开full_page_writes参数,WAL文件不能被类似pg_compresslog的工具去掉full-page writes信息。
4.2.2 pg_basebackup的命令行参数
- -D directory或--pgdata=directory:指定备份的目标目录,即备份到哪儿。如果这个目录或目录路径中的各级父目录不存在,pg_basebackup就会自动创建该目录。如果目录存在,但不为空,则会导致pg_basebackup执行失败。如果备份的输出是tar结果(指定-F tar ,后面会介绍此选项),而-D参数后的目录名写成“-”(中划线),则备份会输出到标准输出,此项功能是为了方便通过管道与其他工具配合使用。
- -F format或--format=format:指定输出的格式。目前支持两种格式,第一种格式是原样输出,即把主数据库中的各个数据文件、配置文件、目录结构都完全一样地写到备份目录中,这种情况下“format”指定为“p”或“plain”;第二种格式是tar格式,相当于把输出的备份文件打包到一个tar文件中,这种情况下“format”应为“t”或“tar”。
- -r,--max-rate=RATE:限速参数,热备份会在主库产生较多的I/O和网络开销,可以用该参数限制速率。速率的默认单位是“kB/s”,当然也可以指定单位“k”或“M”。
- -R,--write-recovery-conf:是否生成recovery.conf文件。
- -x或--xlog:备份时会把备份中主库产生的WAL文件也自动备份出来,这样在恢复数据库时,做出的备份才能应用这些WAL文件把数据库推到一个一致点,然后才能打开备份的数据库。该选项与下面的选项“-X fetch”是完全一样的。使用该选项需要设置wal_keep_segments参数,以保证在备份过程中需要的WAL日志文件不会被覆盖。注意,该参数在PostgreSQL 10版本之后废弃,请用“-X fetch”替代。
- -X method或--xlog-method=method:method可以取的值为“f”“fetch”“s”“stream”,“f” 与“fetch”相同,其含义与“-x”参数是一样的。“s”与“stream”表示的含义相同,均表示备份开始后,启动另一个流复制连接从主库接收WAL日志。这种方式避免了使用“-X f”时,主库上的WAL日志有可能被覆盖而导致失败的问题。但这种方式需要与主库建两个连接,因此使用这种方式时,主库的max_wal_senders参数要设置为大于或等于2的值。
- -z或--gzip:仅能与tar输出模式配合使用,表明输出的tar备份包是经过gzip压缩的,相当于生成了一个*.tar.gz的备份包
- -Z level或--compress=level:指定gzip的压缩级别,可以选1~9的数字,与gzip命令中的压缩级别的含义是一样的,9表示最高压缩率,但也最耗CPU。
- -c fast|spread或--checkpoint=fast|spread:设置Checkpoint的模式是fast还是spread。
- -l label或--label=label:指定备份的一个标识,备份的标识是一个任意字符串,便于今后维护人员识别该备份,该标识就是手动做基础备份时运行“select pg_start_backup('lable')”传递给pg_start_backup函数的参数。在备份集中有一个文件叫“backup_label”,这里面除了记录开始备份时起始的WAL日志的开始位置、Checkpoint的WAL日志位置、备份的开始时间,也记录了该标识串的信息。
- -P或--progress:允许在备份过程中实时地打印备份的进度。当然,所打印的进度不是百分之百精确的,因为在备份过程中,数据库的数据还会发生变化,还会不断产生一些WAL日志。
- -v或--verbose:详细模式,如当使用了-P参数时,还会打印出正在备份哪个具体文件的信息。
- -V或--version:打印pg_basebackup的版本后退出。
- -?或--help:显示帮助信息后退出。 下面是控制连接数据库的参数的说明。
- -h host或--host=host:指定连接的数据库的主机名或IP地址。
- -p port或--port=port:指定连接的端口。
- -s interval或--status-interval=interval:指定向服务器端周期反馈状态的秒数,如果服务器上配置了流复制的超时,当使用--xlog=stream选项时需要设置该参数,默认值为10秒。如果设置为“0”,表示不向服务器反馈状态。
- -U username或--username=username:指定连接的用户名。
- -w或--no-password:指定从来不提示输入密码。
- -W或--password:强制让pg_basebackup出现输入密码的提示。
4.2.3 pg_basebackup使用示例
使用如下命令进行备份:
(base) ➜ standby_test ~/work/cwork/postgresql/debug/bin/pg_basebackup -D backup -Ft -z -P -U postgres -h 192.168.80.20 -p 54322 -W
Password:
24721/24721 kB (100%), 1/1 tablespace
(base) ➜ standby_test ls
backup
(base) ➜ standby_test ls backup
base.tar.gz pg_wal.tar.gz
因为用“-Ft -z”指定了tar和压缩模式,所以在backup目录下生成了两个压缩文件。
如果把base.tar.gz压缩文件解压,其中的backup_label文件的内容如下:
START WAL LOCATION: 0/50005A0 (file 000000010000000000000005)
CHECKPOINT LOCATION: 0/50005D8
BACKUP METHOD: streamed
BACKUP FROM: standby
START TIME: 2024-03-07 11:55:55 UTC
LABEL: pg_basebackup base backup
START TIMELINE: 1
从上面的内容可以看出,如果不指定备份label,pg_basebackup工具生成的label为“pg_basebackup base backup”。
(base) ➜ backup ls
backup_label global pg_ident.conf pg_replslot pg_stat_tmp PG_VERSION postgresql.auto.conf
backup_label.old pg_commit_ts pg_logical pg_serial pg_subtrans pg_wal postgresql.conf
base pg_dynshmem pg_multixact pg_snapshots pg_tblspc pg_wal.tar.gz standby.signal
base.tar.gz pg_hba.conf pg_notify pg_stat pg_twophase pg_xact tablespace_map
而且因为是从一台备库备份过来的,所以之前就有一个backup_label,会重新命名为backup_label.old。
再从另一台机器指定label来进行备份,命令如下:
(base) ➜ standby_test ~/work/cwork/postgresql/debug/bin/pg_basebackup -U postgres -F p -P -X stream -R -D backup2 -l standby01 -h 192.168.80.20 -p 5432 -W
Password:
24719/24719 kB (100%), 1/1 tablespace
(base) ➜ standby_test ls backup2
backup_label pg_commit_ts pg_ident.conf pg_notify pg_snapshots pg_subtrans PG_VERSION postgresql.auto.conf
base pg_dynshmem pg_logical pg_replslot pg_stat pg_tblspc pg_wal postgresql.conf
global pg_hba.conf pg_multixact pg_serial pg_stat_tmp pg_twophase pg_xact standby.signal
(base) ➜ standby_test cat backup2/backup_label
START WAL LOCATION: 0/6000028 (file 000000010000000000000006)
CHECKPOINT LOCATION: 0/6000060
BACKUP METHOD: streamed
BACKUP FROM: master
START TIME: 2024-03-07 12:05:19 UTC
LABEL: standby01
START TIMELINE: 1
上述的命令中使用的连接用户名为“postgres”,输出格式为普通原样输出“-F p”,“-P”参数表示在执行过程中输出备份的进度,“-X stream”参数表示把在备份过程中产生的xlog文件也备份出来,“-R” 参数表示在备份中会生standby.signal文件,并把连接主库的信息放到postgresql.auto.conf中,如果是PostgreSQL 12版本之前会生成配置文件“recovery.conf”,当用此备份启动备库时,只需要简单修改recovery.conf就可以把数据库启动到备库模式。“-D”参数指定了备份文件都生成到环境变量backup2目录下,“-l”参数指定了备份的标识串为“standby01”。
4.3 异步流复制Hot Standby的示例
4.3.1 配置环境
4.3.2 主数据库的配置
要使用流复制,需要允许主库接受流复制的连接,这就需要在pg_hba.conf中做如下配置:
host replication all 0/0 md5
上面这条SQL语句的含义是允许任意用户从任何网络(0/0)网络上发起到本数据库的流复制连接,使用MD5的密码认证。用户“postgres”是该演示环境上的超级用户,当然,换成一个有流复制权限的用户也可以。
要想搭建流复制,需要在主库的postgresql.conf中设置以下几个参数:
listen_addresses = '*'
max_wal_senders = 10
wal_level = replica
注意,一定要把max_wal_senders参数设置成一个大于零的值,在这里设置为“10”,同时需要把wal_level参数设置为“replica”或“logical”。若在数据库启动后再来修改这几个值则需要重启数据库。
另外,min_wal_size参数的默认值为“80MB”,该值通常太小,很容易导致备库失效,也需要设置得大一些:
min_wal_size = 800MB
4.3.3 在Standby上生成基础备份
做完以上准备工作后,就可以使用pg_basebackup生成基础备份了,命令如下:
~/work/cwork/postgresql/debug/bin/pg_basebackup -U postgres -F p -P -X stream -R -D backup2 -l standby01 -h 192.168.80.20 -p 5432 -W
因为使用pg_basebackup命令时使用了“-R”参数,所以也会生成standby.signal文件,同时在postgresql.auto.conf中生成如下内容:
(base) ➜ standby_test cat backup2/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
primary_conninfo = 'user=postgres password=postgres channel_binding=disable host=192.168.80.20 port=5432 sslmode=disable sslcompression=0 sslcertmode=disable sslsni=1 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=postgres gssdelegation=0 target_session_attrs=any load_balance_hosts=disable'
如果没有加“-R”参数,我们也可以手动添加上面的内容。
4.3.4 启动Standby数据库
在启动Standby数据库之前,检查standby数据库postgresql.conf中的参数“hot_standby”是否为“on”,设置该参数是为了让备库是Hot Standby,即可以对外提供只读服务。当然该参数在较新版本的PostgreSQL中默认已经被设置成“on”。
base) ➜ standby_test cat backup2/postgresql.conf | grep hot
#old_snapshot_threshold = -1 # 1min-60d; -1 disables; 0 is immediate
#hot_standby = on # "off" disallows queries during recovery
#hot_standby_feedback = off # send info from standby to prevent
如果备库连接到主库上,在主库的pg_stat_replication视图中,就可以看到从备库过来的流复制连接:
postgres=# select client_addr,client_port,state,sync_state from pg_stat_replication;
client_addr | client_port | state | sync_state
-------------+-------------+-----------+------------
172.28.0.1 | 62273 | streaming | async
如果看不到备库过来的连接,说明备库没有连过来,需要检查备库的日志文件查看原因。如果看到的流复制状态“state”的值不是“streaming”,也说明备库的流复制有问题。
因为Hot Standby是只读的,所以如果在Standby上做修改,会操作失败。
4.3.5 switchover(交换主备库的角色)
对于Oracle数据库的DBA来说,切换Oracle数据库的主备库之间的角色的过程叫“switchover”,Oracle提供了相应的“switchover”的一些较复杂的命令和过程。对于PostgreSQL数据库来说,切换操作的步骤比较简单:
- 先停主库,再停备库。
- 在原主库的数据目录中建文件“standby.signal”,并配置连接新主库的流复制参数。
- 把原备库数据目录下的文件“standby.signal”重命名或直接删除
- 启动原备库,这时该备库变成了主库
- 启动原主库,这时该主库变成了备库
4.3.6 failover(故障切换)
通常故障切换称为“Failover”。异步复制时,如果主库出现了问题,可以激活备库作为主库提供服务。在PostgreSQL9.1版本之前是在recovery.conf中配置一个trigger文件,当备库检测到该文件时,就自动把自己激活成主库,PostgreSQL9.1版本之后提供了命令“pg_ctl promote”来激活备库,所以现在很少有人再以配置trigger文件的方式激活备库了。
原主库出现问题后,通常这些故障并没有导致数据丢失,如宕机、机器重启的故障。当故障解决之后,通常我们会把原主库转换成新主库的Standby备库,该转换一般来说需要重新搭建备库。这是因为原主库的一些数据没有同步过去就把备库激活了,备库相当于丢失了一些数据。而重新搭建备库的话,如果数据库很大,基础备份会执行很长时间,为了解决这个问题,从PostgreSQL 9.5版本开始提供pg_rewind命令,不需要复制太多的数据就可以把原主库转换成新主库的备库。该命令相当于把原主库的数据“回滚”到新主库激活时的状态,当然这里所说的“回滚”不是真的“回滚”,只是为了让我们更好地理解pg_rewind的作用。
使用pg_rewind命令要求主库必须把参数“wal_log_hints”设置成“on”或主库在建数据库实例时打开了checksum,这样配置的主库在出现故障时才能使用pg_rewind命令。当然这样做之后,数据库会产生更多的WAL日志,所以数据库默认是没有打开checksum参数的 。数据库实例打开checksum参数的方法是,在用initdb命令初始化数据库实例时使用“-k” 或“--data-checksums”参数。
如果我们没有把参数“wal_log_hints”或“checksum”打开,运行pg_rewind时会报错。
pg_rewind执行完之后,需要手动建文件“standby.signal”。
4.4 同步流复制的Standby数据库
4.4.1 同步流复制架构
PostgreSQL异步流复制的缺点是当主库损坏的时候,激活备库后会丢失一些数据,这对于一些不允许丢失数据的应用来说是不可接受的,所以PostgreSQL从9.1版本开始提供同步流复制的功能,解决了主备库切换时丢失数据的问题。同步复制要求WAL日志写入Standby数据库后commit才能返回,所以Standby库出现问题时,会导致主库被hang住。解决这个问题的方法是启动两个Standby数据库,这两个Standby数据库只要有一个是正常运行的就不会让主库hang住。所以在实际应用中,同步流复制,总是有一个主库和两个以上的Standby备库。
即使是同步复制,如果因主库发生临时故障激活了其中一个备库,要想把原主库转换成新主库的备库,仍然需要用pg_rewind处理一下才行,这是因为虽然是同步复制,但并不是把主库的WAL日志完全同步地传输到备库,同步只是到事务提交时才保证其已经传输到了备库,一些未提交事务的WAL日志可能还没有传输到备库,因此激活备库时,还是会丢失一些WAL日志。当然对于用户来说,未提交事务的WAL日志丢失,并不会导致用户数据的丢失。
4.4.2 同步流复制的配置
同步复制的配置主要是在主库上配置参数“synchronous_standby_names”,该参数指定多个Standby的名称,各个名称用逗号分隔,而Standby名称是在Standby连接到主库时由连接参数“application_name”指定的。要使用同步复制,在Standby数据库中primary_conninfo参数一定要指定连接参数“application_name”。primary_conninfo参数的配置示例如下:
primary_conninfo = 'application_name=standby01 user=postgres password=XXXXXX host=10.0.3.101 port=5432 ss
lmode=disable sslcompression=1'
在PostgreSQL 9.6版本之前,只允许有一个同步的Standby备库,即“synchronous_standby_names”参数的配置值只有一种格式:
standby_name [, ...]
例如,我们配置了“synchronous_standby_names='s1,s2,s3'”,虽然配置了多个备库s1、s2、s3,但只有第一个备库s1是同步的,其他均是潜在的同步备库,即只要WAL日志传递到第一个备库s1,事务commit就可以返回了,当第一个备库s1出现问题时,第二个备库s2才会提升为同步备库。
num_sync ( standby_name [, ...] )
其中“num_sync”是一个数字,如“synchronous_standby_names='2 (s1,s2,s3)”表示,WAL日志必须传到前两个备库“s1”和“s2”,事务commit才可以返回。所以之前版本中的配置“s1,s2,s3”相当于“1(s1,s2,s3)”备。
从PostgreSQL 10版本开始,可以设置基于quorum的方式设置备库,新增的格式如下:
ANY num_sync ( standby_name [, ...] )
例如,我们配置“synchronous_standby_names='ANY 2 (s1,s2,s3)'”时,只要WAL日志传到了任意两个备库,事务commit就可以返回了。
影响同步复制的还有一个参数“synchronous_commit”,该参数可以取的值有以下几个:
- remote_apply:WAL日志被传到备库并被apply,事务commit才返回。
- on:WAL日志被传到备库并被持久化(不必等其被apply),事务commit才返回。
- remote_write:WAL日志被传到备库的内存中(不必等其被持久化),事务commit才返回。
- local:WAL日志被本地持久化后(不用管远程)事务commit就可以返回。
- off:不必等WAL日志被本地持久化,也不管是否传到远程,事务commit都可以立即返回。
由上面说明即可联想到同步复制,synchronous_commit的可选值为“on”“remote_apply”“remote_write”。
4.4.3 检查备库及流复制情况
可以通过一些函数或视图来检查备库的状态和流复制的情况。
4.4.3.1 检查异步流复制的情况
查看流复制的信息可以使用主库上的视图“pg_stat_replication”,如果流复制是异步的,查询视图“pg_stat_replication”看到的信息如下;
postgres=# select pid,state,client_addr, sync_priority,sync_state from pg_stat_replication;
pid | state | client_addr | sync_priority | sync_state
-----+-----------+-------------+---------------+------------
650 | streaming | 10.0.3.102 | 0 | async
614 | streaming | 10.0.3.103 | 0 | async
(2 rows)
从上面的运行结果中可以看到sync_state字段显示的信息为“async”。
另外,pg_stat_replication视图中的以下几个字段记录了一些WAL日志的位置。
- sent_lsn:发送WAL的位置。
- write_lsn:可以认为是备库已经接收到了这部分日志,但还没有刷到磁盘中。
- flush_lsn:备库已经把WAL日志刷到磁盘中的位置。
- replay_lsn:备库应用日志的位置。
查看备库落后主库多少字节的WAL日志,可以使用如下SQL命令:
postgres=# select pg_wal_lsn_diff(pg_current_wal_lsn(),replay_lsn) from pg_stat_replication;
pg_wal_lsn_diff
----------------
11815016
上面的SQL语句中,使用pg_current_wal_lsn ()获得当前主库的WAL日志的位置,replay_location为当前备库应用WAL日志的位置,再使用函数“pg_wal_lsn_diff”就可以算出差异的字节数,注意,上面示例中算出的结果的单位是字节。
注意,在PostgreSQL10及以上版本中与WAL日志有关的函数的名称有所改变,名称中的“xlog”改成了“wal”,“location”改成了“lsn”,pg_stat_replication中列名也有类似的变化:
- “pg_xlog_location_diff”改成了“pg_wal_lsn_diff”。
- “pg_current_xlog_location”改成了“pg_current_wal_lsn”。
- “replay_location”改成了“replay_lsn”。
PostgreSQL 10及以上版本在pg_stat_replication中还提供了以下3个落后时间的字段。
- write_lag:备库已接收到的日志目前落后主库的时间间隔。
- flush_lag:备库持久化的日志目前落后主库的时间间隔。
- replay_lag:备库已经应用过的日志目前落后主库的时间间隔。
这几个参数都是“时间间隔(interval)”的类型。
4.4.3.2 检查同步流复制的情况
同步流复制的环境中,在主库查询pg_stat_replication可以看到如下信息:
postgres=# select pid,state,client_addr, sync_priority,sync_state from pg_stat_replication;
pid | state | client_addr | sync_priority | sync_state
-----+-----------+-------------+---------------+------------
599 | streaming | 10.0.3.102 | 1 | sync
614 | streaming | 10.0.3.103 | 2 | potential
(2 rows)
可以看到pg02的优先级是“1”,pg03的优先级是“2”,这个优先级是由synchronous_standby_names参数配置中的顺序决定的。目前主数据库与pg02处于同步“sync”,而pg03的状态为“potential”,表示它是一个潜在的同步Standby备库,当pg02损坏时,pg03会切换到同步状态,这时关掉pg02,可看到如下内容:
postgres=# select pid,state,client_addr, sync_priority,sync_state from pg_stat_replication;
pid | state | client_addr | sync_priority | sync_state
-----+-----------+-------------+---------------+------------
614 | streaming | 10.0.3.103 | 2 | sync
(1 row)
再次启动pg02,此时查看同步情况如下:
postgres=# select pid,state,client_addr, sync_priority,sync_state from pg_stat_replication;
pid | state | client_addr | sync_priority | sync_state
-----+-----------+-------------+---------------+------------
650 | streaming | 10.0.3.102 | 1 | sync
614 | streaming | 10.0.3.103 | 2 | potential
(2 rows)
从中可以发现pg03又从“sync”状态变成了“potential”状态,pg02重新变成了“同步状态” 。
4.4.3.3 pg_stat_replication视图详解
可以在主库上把WAL位置转换成WAL文件名和偏移量,命令如下:
postgres=# SELECT * FROM pg_walfile_name_offset('0/5F8862F0');
file_name | file_offset
--------------------------+-------------
00000001000000000000005F | 8938224
(1 row)
4.4.3.4 查看备库的状态
前面讲解了在主库上通过查看pg_stat_replication视图获得备库流复制状态的方法,在备库上也可以通过查看视“pg_stat_wal_receiver”来查看流复制的状态:
postgres=# \x
Expanded display is on.
postgres=# select * from pg_stat_wal_receiver;
-[ RECORD 1 ]---------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 31
status | streaming
receive_start_lsn | 0/7000000
receive_start_tli | 1
received_lsn | 0/70002E0
received_tli | 1
last_msg_send_time | 2024-03-15 06:54:56.238236+00
last_msg_receipt_time | 2024-03-15 06:54:56.238333+00
latest_end_lsn | 0/70002E0
latest_end_time | 2024-03-14 06:44:35.202538+00
slot_name |
sender_host | 192.168.80.20
sender_port | 5432
conninfo | user=postgres password=******** channel_binding=disable dbname=replication host=192.168.80.20 port=5432 fallback_application_name=walreceiver sslmode=disable sslcompression=0 sslsni=1 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=any
postgres=#
从上面的示例中可以看出,这个视图实际上是显示备库上WAL接收进程的状态,其中的主要字段的说明如下。
- pid:WAL接收进程的PID。
- status:状态,只有“streaming”是正常状态。
- receive_start_lsn:WAL接收进程启动时使用的第一个WAL日志的位置。
- receive_start_tli:WAL接收进程启动时使用的第一个时间线编号。
- received_lsn:已经接收到并且已经被写入磁盘的最后一个WAL日志的位置。
- received_tli:已经接收到并且已经被写入磁盘的最后一个WAL日志的时间线编号。
- last_msg_send_time:接收到最后一条WAL日志消息后,向主库发回确认消息的发送时间。
- last_msg_receipt_time:备库接收到最后一条WAL日志消息的接收时间。
- latest_end_lsn:报告给主库最后一个WAL日志的位置。
- latest_end_time:报告给主库最后一个WAL日志的时间。
- slot_name:使用的复制槽的名称。
- conninfo:连接主库的连接串,密码等安全相关的信息会被隐去。
如何判断数据库处于备库的状态?如果数据库处于Hot Standby状态,可以连接到数据库中执行pg_is_in_recovery()函数,如果是在主库上,此函数返回的值是“False”,如果是在备库上,返回的值是“True”,示例如下。
在主库上执行select pg_is_in_recovery()函数的示例如下:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)
在备库上执行pg_is_in_recovery()函数的示例如下:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
如果备库不是Hot Standby状态,不能直接连接上去,这时可以使用命令行工具“pg_controldata”来进行判断,在主库上看到“Database cluster state”为“in production”,命令如下:
root@eb2e0ae36696:/# pg_controldata
pg_control version number: 1201
Catalog version number: 201909212
Database system identifier: 7337595217489322023
Database cluster state: in production
pg_control last modified: Thu 14 Mar 2024 06:44:29 AM UTC
...
...
在备库上看到“Database cluster state”为“in archive recovery”,命令如下:
root@6f01eeed1bd5:/# pg_controldata
pg_control version number: 1201
Catalog version number: 201909212
Database system identifier: 7337595217489322023
Database cluster state: in archive recovery
pg_control last modified: Thu 14 Mar 2024 06:44:43 AM UTC
...
...
在Hot Standby备库上,还可以执行如下函数查看备库接收的WAL日志和应用WAL日志的状态:
- pg_last_wal_receive_lsn()
- pg_last_wal_replay_lsn()
- pg_last_xact_replay_timestamp()
实例如下:
postgres=# set timezone = 8;
SET
postgres=# select pg_last_wal_receive_lsn(),pg_last_wal_replay_lsn(),pg_last_xact_replay_timestamp();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn | pg_last_xact_replay_timestamp
-------------------------+------------------------+-------------------------------
0/70002E0 | 0/70002E0 |
(1 row)
4.5 Hot Standby的限制
前面已经说过,PostgreSQL支持在备库做只读查询,这样的备库就叫Hot Standby。在Hot Standby备库上执行查询时有一些限制。
4.5.1 Hot Standby的查询限制
DML语句(如INSERT、UPDATE、DELETE、COPY FROM、TRUNCATE等)和DDL(如CREATE、DROP、ALTER、COMMENT等)都不能在Hot Standby备库上执行,这很好理解。另外,“SELECT...FOR SHARE|UPDATE”语句在Hot Standby备库中也不能执行,因为在PostgreSQL中,行锁是要更新数据行的。如果在Hot Standby备库执行上述SQL语句,会报如下错误:
postgres=# create table test(id int);
ERROR: cannot execute CREATE TABLE in a read-only transaction
postgres=# select * from test for update;
ERROR: cannot execute SELECT FOR UPDATE in a read-only transaction
虽然在Hot Standby备库中行锁不能使用,但部分类型的表锁是可以使用的,但要注意,这部分表锁需要在BEGIN启动的事务块中使用,直接使用会报错.在Hot Standby备库上可以加以下类型的表锁:
- ACCESS SHARE。
- ROW SHARE。
- ROW EXCLUSIVE MODE。
也就是说,比ROW EXCLUSIVE MODE级别高的表锁都是不能执行的,或者说,自己和自己互斥的锁和SHARE类型的表锁都不能执行。
在Hot Standby备库上,部分事务管理语句都可以执行,如上面示例中的BEGIN、END,但下面的语句不能执行:
- BEGIN READ WRITE,START TRANSACTION READ WRITE。
- SET TRANSACTION READ WRITE,SET SESSION CHARACTERISTICS AS TRANS ACTION READ WRITE。
- SET transaction_read_only=off。
在Hot Standby备库上,两阶段提交的命令也不能执行:
- PREPARE TRANSACTION。
- COMMIT PREPARED。
- ROLLBACK PREPARED
在Hot Standby备库中,序列中会导致更新的函数也不能执行:
- nextval()。
- setval()。
在Hot Standby备库中,消息通知的语句也不能执行:
- LISTEN。
- UNLISTEN。
- NOTIFY
但在通常的只读事务中,序列的更新函数和消息通知的语句都是可以执行的,也就是说,在HOT Standby备库中执行SQL语句的限制比只读事务中的限制更多。
在Hot Standby备库中,参数“transaction_read_only”总设置为“ON”,而且不能改变。可以使用“SHOW transaction_read_only”查看此参数的状态。
4.5.2 Hot Standby的查询冲突处理
主库上的一些操作会与Hot Standby备库上的查询产生冲突,会导致正在执行的查询被取消并报如下错误:
ERROR:canceling statement due to conflict with recove
导致冲突的原因有以下几个:
- 主库上运行的VACUUM清理掉了备库上的查询需要的多版本数据。
- 主库上执行LOCK命令或各种DDL语句会在表上产生Exclusive锁,而在备库上对这些表进行查询时,这两个操作之间会有冲突。
- 在主库上删除了一个表空间,而备库上的查询需要存放一些临时文件在此表空间中。
- 在主库上删除了一个数据库,而备库上有很多session还连接在该数据库上。
当发生冲突时,处理的方法有以下几种:
- 让备库上的应用WAL日志的过程等待一段时间,等备库上的查询结束后再应用WAL 日志。
- 取消备库上正在执行的查询
另外,在主库上删除一个数据库时,备库上连接到此数据库上的session都将被断开连接。
如果备库上的查询运行的时间很短,可以让备库上WAL日志的应用过程等一会儿。但是如果备库上的查询是一个大查询,需要运行很长的时间,让应用WAL日志的过程一直等待,会导致备库延迟主库太多的问题,因此PostgreSQL在postgresql.conf中增加了两个参数用于控制应用WAL日志的最长等待时间,超过设定时间就会取消备库上正在执行的SQL查询。这两个参数的说明如下。
- max_standby_archive_delay:备库从WAL归档中读取时的最大延迟。默认为30秒,如果设置为-1,则会一直等待。
- max_standby_streaming_delay:备库从流复制中读取WAL时的最大延迟。默认为30秒,如果设置为-1,则会一直等待。
如果备库用作主库的高可用切换,则可以把以上参数设置得小一些,这样可以保证备库不会落后主库太多;如果备库就是用来执行一些大查询的,可以把这两个参数设置成较大的值。
大多数冲突发生的原因是主库上把备库需要的多版本数据给清理掉了,这时可以通过在备库上的postgresql.conf中设置参数“hot_standby_feedback”为“true”来解决此问题。设置此参数为“true”后,备库会通知主库,哪些多版本数据在备库上还需要,这样主库上的AutoVacuum就不会清理掉这些数据,就能大大减少冲突的发生。当然还有一个办法是把主库上的参数“vacuum_defer_cleanup_age”的值调得大一些,以延迟清理多版本数据。
当然即使设置了hot_standby_feedback等参数,仍然会有一些查询因为冲突而被取消执行,所以连接到备库的应用程序最好能检测到这个错误并能再次执行被取消的查询。
4.6 恢复配置详解
4.6.1 归档恢复配置项
归档恢复配置项主要有以下3个:
- restore_command:指定Standby如何获得WAL日志文件,通常是配置一个拷贝命令,从备份目录中把WAL日志文件拷贝过来。
- archive_cleanup_command:清理Standby数据库机器上不需要的WAL日志文件。
- recovery_end_command:恢复完成后,可以执行一个命令。
使用这几个配置项就可以搭建起一个从归档日志文件中恢复的Standby数据库。例如,在主库上配置archive_command参数,把WAL文件复制到Standby库的一个目录中,命令如下:
archive_command = 'scp %p 192.168.1.52:/data/archivedir/%f.mid && ssh 192.168.1.52 "mv /data/archivedir/%
f.mid /data/archivedir/%f"'
然后在Standby数据库中的postgresql.conf中配置restore_command参数,命令如下:
restore_command = 'cp /data/archivedir /%f "%p"'
另两个参数“archive_cleanup_command”“recovery_end_command”是可选的,其中archive_cleanup_command参数可以用来清理上面示例中“/data/archivedir”目录中的WAL日志文件。从上面的示例中可以知道,当主库不断地把WAL日志文件复制到Standby备库的“/data/archivedir”目录中时,一定要有清理机制,否则就会把此目录的空间填满。清理的原则通常是清除Standby已使用完的WAL日志文件。contrib目录中提供了一个命令行的工具“pg_archivecleanup”以便实现清理工作,archive_cleanup_comand参数的配置内容如下:
archive_cleanup_command = 'pg_archivecleanup /data/archivedir %r'
下面介绍主库上的归档配置项。主库上的归档配置项有如下3个,都是在postgresql.conf文件中配置。
- archive_mode:是否开启归档。如果想以归档的方式搭建Standby数据库,则此参数设置为“on”。
- archive_command:执行归档的命令。
- archive_timeout:如果主库在某段时间内比较闲,可能会很长时间才产生WAL日志文件,这会导致主库和Standby库之间有较大的延迟,这时可以配置此参数。把此参数配置成一个整数(单位是秒),表示设定的秒数内会强制数据库切换一个WAL日志文件。
注意,被强制切换的WAL文件和正常WAL文件一样大。因此把archive_timeout设置成很小的值是不明智的,会占用大量空间。
4.6.2 Recovery Target配置
通常Standby备库的恢复是一直进行的,如果想让Standby恢复到一个指定的点后就暂停,需要使用以下配置参数:
- recovery_target:目前此参数只能配置为空或“immediate”,配置为“immediate”,则Standby恢复到一个一致性的点时就立即停止恢复。该配置通常用在热备份中。完成一个热备份后,如果想使用这个热备份,希望在应用WAL日志把热备份恢复到一个可以打开的 点时立即打开此数据库,就需要配置此参数。
- recovery_target_name:这是9.1版本之后才提供的参数。在主库上可以创建一个恢复点,然后让Standby恢复到这个恢复点,此参数用来指定该恢复点的名称。创建恢复点是通过调用函数pg_create_restore_point()来完成的。
- recovery_target_time:这是9.1版本之后才提供的参数,用于指定恢复到哪个时间点。恢复到设定时间点之前最近的一致点还是该时间点之后最近的一致点是由后面的参数“recovery_target_inclusive”来指定的。
- recovery_target_xid:这是9.1版本之后才提供的参数,指定恢复到哪个指定的事务。注意,事务ID是按顺序分配的,但事务完成的顺序与分配的顺序是不一样的。后分配的ID的事务可能会先完成。
- recovery_target_inclusive:指定恢复到恢复目标(recovery target)之后还是之前。默认为恢复目标之后,即值为“true”。
- recovery_target_timeline:指定恢复的时间线。默认只恢复到当前的时间线,而不会切换到新的时间线。通常需要把此参数设置为“latest”,这样就会恢复到离当前最近的时间线。
- pause_at_recovery_target:指定到达恢复目标后,Standby数据库恢复是否暂停。默认为“true”。该参数用于检查当前Standby是否恢复到了需要的点。在恢复暂停后,执行SQL语句来检查是否是需要的时间点,如果不是,可以停止Standby数据库,然后重新配置“recovery_target_*”参数指定新的恢复目标点,再进行恢复,直到把Standby推到需要的时间点。到达该时间点后,就可以使用pg_wal_replay_resume()继续进行恢复。
4.6.3 Standby Server配置
备库中还有用于配置Standby Server的以下参数,各参数的说明如下。
- standby_mode:是否运行在Standby模式下。只有PostgreSQL 12之前的版本中才有此配置项。PostgreSQL 12版本之后用文件“standby.signal”表示是否运行在Standby模式下。
- primary_conninfo:在流复制中,指定如何连接主库,是一个标准的libpq连接串。
- primary_slot_name:指定复制槽(Replication Slot)。这是PostgreSQL 9.4版本之后增加的参数,是一个可选参数。
- promote_trigger_file:指定激活Standby的触发文件。Standby数据库发现存在此文件时,就会把Standby激活为主库。不配置此项也没有关系,可以使用pg_ctl promote来激活Standby数据库。在PostgreSQL12版本之前,此配置项的名称为“trigger_file”,配置在recovery.conf中。
- recovery_min_apply_delay:PostgreSQL 9.4版本之后增加的参数,此参数可以让Standby落后主库一段时间。在PostgreSQL 9.4版本之前,很难让Standby落后主库指定的时间。例如,有如下场景,创建了一个Standby库用于防止逻辑误删除操作,如果该库被设置为即时与主库同步,而有人恰巧不小心删除了某一张表,那可能就会导致Standby上的这张表也很快被删除,这时如果让Standby延迟恢复一段时间,那就可以在设定的延迟时间内从Standby数据库中恢复这张表的数据。该参数指定一个时间值,如“5min”。设置此参数后,hot_standby_feedback也会相应被延迟。
4.7 流复制的注意事项
4.7.1 min_wal_size参数的配置
使用流复制建好备库后,如果由于各种原因备库接收日志的速度较慢,而主库产生日志的速度很快,这容易导致主库上的WAL日志还没有传递到备库就会被覆盖,如果被覆盖的WAL日志文件又没有归档备份,那么备库就再也无法与主库同步了,这会导致备库需要重新搭建。为了避免这种情况发生,PostgreSQL提供了一个配置参数“wal_keep_segments”。该参数的含义是,无论如何都要在主库上保留wal_keep_segements个WAL日志文件。默认此参数为“0”,表示并不专门为Standby保留WAL日志文件。通常需要把此参数配置成一个安全的值,如“64”,表示将为Standby保留64个WAL日志文件。当然保留WAL日志文件会占用一定的磁盘空间,每个WAL日志文件的大小通常是16MB,如果设置为“64”,就可能会多占用64×16MB=1G空间。所以如果磁盘空间允许,可以把此参数设置得大一些,这样,WAL日志来不及传输到备库导致的备库需要重新搭建的风险就会小一些。
4.7.2 vacuum_defer_cleanup_age参数的配置
在主库上,Vacuum进程知道哪些旧版本的数据会被当前数据库中的查询使用,从而不清理这些数据。但对于Hot Standby上的查询的数据需要,主库是不知道的,所以主库上的Vacuum可能会把Hot Standby上的查询还需要的旧版本数据清理掉,这会导致Standby上的查询失败。为了降低Hot Standby因为这个原因失败的概率,可以设置vacuum_defer_cleanup_age参数,让主库延迟清理。该参数的含义是延迟清理多少个事务,当然也可以通过在备库上设置参数“hot_standby_feedback”为“true”来减少此问题的发生。